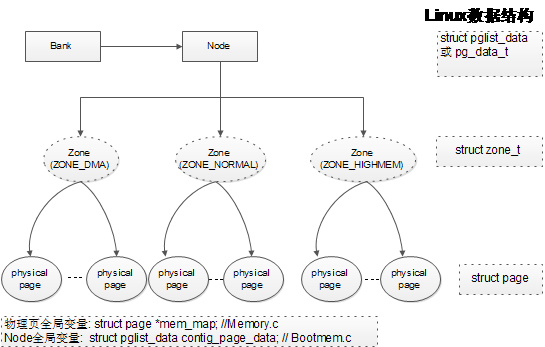
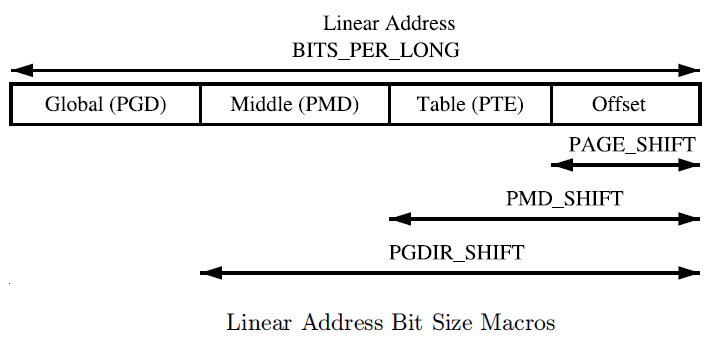
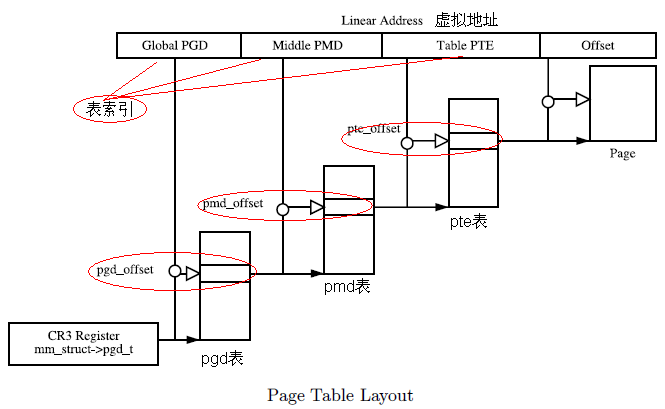
Linux内核中,关于虚存管理的最基本的管理单元应该是struct vm_area_struct了,它描述的是一段连续的、具有相同访问属性的虚存空间,该虚存空间的大小为物理内存页面的整数倍。
下面是struct vm_area_struct结构体的定义:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 | |
vm_area_struct结构所描述的虚存空间以vm_start、vm_end成员表示,它们分别保存了该虚存空间的首地址和末地址后第一个字节的地址,以字节为单位,所以虚存空间范围可以用[vm_start, vm_end)表示。
通常,进程所使用到的虚存空间不连续,且各部分虚存空间的访问属性也可能不同。所以一个进程的虚存空间需要多个vm_area_struct结构来描述。在vm_area_struct结构的数目较少的时候,各个vm_area_struct按照升序排序,以单链表的形式组织数据(通过vm_next指针指向下一个vm_area_struct结构)。但是当vm_area_struct结构的数据较多的时候,仍然采用链表组织的化,势必会影响到它的搜索速度。针对这个问题,vm_area_struct还添加了vm_avl_hight(树高)、vm_avl_left(左子节点)、vm_avl_right(右子节点)三个成员来实现AVL树,以提高vm_area_struct的搜索速度。
假如该vm_area_struct描述的是一个文件映射的虚存空间,成员vm_file便指向被映射的文件的file结构,vm_pgoff是该虚存空间起始地址在vm_file文件里面的文件偏移,单位为物理页面。
一个程序可以选择MAP_SHARED或MAP_PRIVATE共享模式将一个文件的某部分数据映射到自己的虚存空间里面。这两种映射方式的区别在于:MAP_SHARED映射后在内存中对该虚存空间的数据进行修改会影响到其他以同样方式映射该部分数据的进程,并且该修改还会被写回文件里面去,也就是这些进程实际上是在共用这些数据。而MAP_PRIVATE映射后对该虚存空间的数据进行修改不会影响到其他进程,也不会被写入文件中。
来自不同进程,所有映射同一个文件的vm_area_struct结构都会根据其共享模式分别组织成两个链表。链表的链头分别是:vm_file->f_dentry->d_inode->i_mapping->i_mmap_shared,vm_file->f_dentry->d_inode->i_mapping->i_mmap。而vm_area_struct结构中的vm_next_share指向链表中的下一个节点;vm_pprev_share是一个指针的指针,它的值是链表中上一个节点(头节点)结构的vm_next_share(i_mmap_shared或i_mmap)的地址。
进程建立vm_area_struct结构后,只是说明进程可以访问这个虚存空间,但有可能还没有分配相应的物理页面并建立好页面映射。在这种情况下,若是进程执行中有指令需要访问该虚存空间中的内存,便会产生一次缺页异常。这时候,就需要通过vm_area_struct结构里面的vm_ops->nopage所指向的函数来将产生缺页异常的地址对应的文件数据读取出来。
vm_flags主要保存了进程对该虚存空间的访问权限,然后还有一些其他的属性。vm_page_prot是新映射的物理页面的页表项pgprot的默认值。
原文:http://oss.org.cn/kernel-book/ch06/6.4.2.htm
6.4.2 进程的虚拟空间
如前所述,每个进程拥有3G字节的用户虚存空间。但是,这并不意味着用户进程在这3G的范围内可以任意使用,因为虚存空间最终得映射到某个物理存储空间(内存或磁盘空间),才真正可以使用。
那么,内核怎样管理每个进程3G的虚存空间呢?概括地说,用户进程经过编译、链接后形成的映象文件有一个代码段和数据段(包括data段和bss段),其中代码段在下,数据段在上。数据段中包括了所有静态分配的数据空间,即全局变量和所有申明为static的局部变量,这些空间是进程所必需的基本要求,这些空间是在建立一个进程的运行映像时就分配好的。除此之外,堆栈使用的空间也属于基本要求,所以也是在建立进程时就分配好的,如图6.16所示:
 进程虚拟空间(3G)!
进程虚拟空间(3G)!
图6.16 进程虚拟空间的划分
由图可以看出,堆栈空间安排在虚存空间的顶部,运行时由顶向下延伸;代码段和数据段则在低部,运行时并不向上延伸。从数据段的顶部到堆栈段地址的下沿这个区间是一个巨大的空洞,这就是进程在运行时可以动态分配的空间(也叫动态内存)。
进程在运行过程中,可能会通过系统调用mmap动态申请虚拟内存或释放已分配的内存,新分配的虚拟内存必须和进程已有的虚拟地址链接起来才能使用;Linux 进程可以使用共享的程序库代码或数据,这样,共享库的代码和数据也需要链接到进程已有的虚拟地址中。在后面我们还会看到,系统利用了请页机制来避免对物理内存的过分使用。因为进程可能会访问当前不在物理内存中的虚拟内存,这时,操作系统通过请页机制把数据从磁盘装入到物理内存。为此,系统需要修改进程的页表,以便标志虚拟页已经装入到物理内存中,同时,Linux 还需要知道进程虚拟空间中任何一个虚拟地址区间的来源和当前所在位置,以便能够装入物理内存。
由于上面这些原因,Linux 采用了比较复杂的数据结构跟踪进程的虚拟地址。在进程的 task_struct结构中包含一个指向 mm_struct 结构的指针。进程的mm_struct 则包含装入的可执行映象信息以及进程的页目录指针pgd。该结构还包含有指向 vm_area_struct 结构的几个指针,每个 vm_area_struct 代表进程的一个虚拟地址区间。
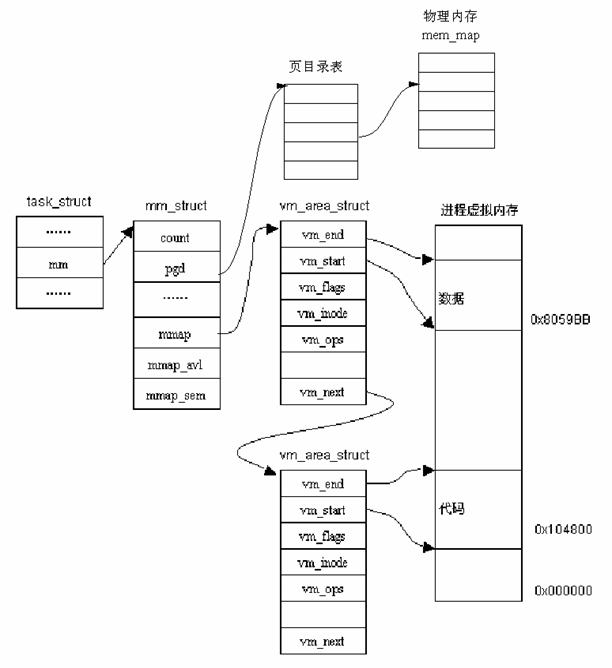
图6.17 进程虚拟地址示意图
图 6.17是某个进程的虚拟内存简化布局以及相应的几个数据结构之间的关系。从图中可以看出,系统以虚拟内存地址的降序排列 vm_area_struct。在进程的运行过程中,Linux 要经常为进程分配虚拟地址区间,或者因为从交换文件中装入内存而修改虚拟地址信息,因此,vm_area_struct结构的访问时间就成了性能的关键因素。为此,除链表结构外,Linux 还利用 红黑(Red_black)树来组织 vm_area_struct。通过这种树结构,Linux 可以快速定位某个虚拟内存地址。
当进程利用系统调用动态分配内存时,Linux 首先分配一个 vm_area_struct 结构,并链接到进程的虚拟内存链表中,当后续的指令访问这一内存区间时,因为 Linux 尚未分配相应的物理内存,因此处理器在进行虚拟地址到物理地址的映射时会产生缺页异常(请看请页机制),当 Linux 处理这一缺页异常时,就可以为新的虚拟内存区分配实际的物理内存。
在内核中,经常会用到这样的操作:给定一个属于某个进程的虚拟地址,要求找到其所属的区间以及vma_area_struct结构,这是由find_vma()来实现的,其实现代码在mm/mmap.c中:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 | |
这个函数比较简单,我们对其主要点给予解释:
·参数的含义:函数有两个参数,一个是指向mm_struct结构的指针,这表示一个进程的虚拟地址空间;一个是地址,表示该进程虚拟地址空间中的一个地址。
·条件检查:首先检查这个地址是否恰好落在上一次(最近一次)所访问的区间中。根据代码作者的注释,命中率一般达到35%,这也是mm_struct结构中设置mmap_cache指针的原因。如果没有命中,那就要在红黑树中进行搜索,红黑树与AVL树类似。
·查找节点:如果已经建立了红黑树结构(rb_rode不为空),就在红黑树中搜索。
·如果找到指定地址所在的区间,就把mmap_cache指针设置成指向所找到的vm_area_struct结构。
·如果没有找到,说明该地址所在的区间还没有建立,此时,就得建立一个新的虚拟区间,再调用insert_vm_struct()函数将新建立的区间插入到vm_struct中的线性队列或红黑树中。
原文:http://bbs.chinaunix.net/archiver/?tid-2058683.html
Linux sys_exec中可执行文件映射的建立及读取
- 创建一个vm_area_struct;
- 圈定一个虚用户空间,将其起始结束地址(elf段中已设置好)保存到vm_start和vm_end中;
- 将磁盘file句柄保存在vm_file中;
- 将对应段在磁盘file中的偏移值(elf段中已设置好)保存在vm_pgoff中;
- 将操作该磁盘file的磁盘操作函数保存在vm_ops中;
- 注意这里没有为对应的页目录表项创建页表,更不存在设置页表项了;