与 netif_rx_schedule_prep(dev) 相似,但是没有判断网卡设备是否 Up 及运行,不建议使用
1
netif_rx_complete(dev)
用于将网卡接口从轮询列表中移除,一般在轮询函数完成之后调用该函数。
1
__netif_rx_complete(dev)
Newer newer NAPI
其实之前的 NAPI(New API) 这样的命名已经有点让人忍俊不禁了,可见 Linux 的内核极客们对名字的掌控,比对代码的掌控差太多,于是乎,连续的两次对 NAPI 的重构,被戏称为 Newer newer NAPI 了。
与 netif_rx_complete(dev) 类似,但是需要确保本地中断被禁止
Newer newer NAPI
在最初实现的 NAPI 中,有 2 个字段在结构体 net_device 中,分别为轮询函数 poll() 和权重 weight,而所谓的 Newer newer NAPI,是在 2.6.24 版内核之后,对原有的 NAPI 实现的几次重构,其核心是将 NAPI 相关功能和 net_device 分离,这样减少了耦合,代码更加的灵活,因为 NAPI 的相关信息已经从特定的网络设备剥离了,不再是以前的一对一的关系了。例如有些网络适配器,可能提供了多个 port,但所有的 port 却是共用同一个接受数据包的中断,这时候,分离的 NAPI 信息只用存一份,同时被所有的 port 来共享,这样,代码框架上更好地适应了真实的硬件能力。Newer newer NAPI 的中心结构体是napi_struct:
NAPI 结构体
123456789101112131415161718192021222324252627
/*
* Structure for NAPI scheduling similar to tasklet but with weighting
*/
struct napi_struct {
/* The poll_list must only be managed by the entity which
* changes the state of the NAPI_STATE_SCHED bit. This means
* whoever atomically sets that bit can add this napi_struct
* to the per-cpu poll_list, and whoever clears that bit
* can remove from the list right before clearing the bit.
*/
struct list_head poll_list;
unsigned long state;
int weight;
int (*poll)(struct napi_struct *, int);
#ifdef CONFIG_NETPOLL
spinlock_t poll_lock;
int poll_owner;
#endif
unsigned int gro_count;
struct net_device *dev;
struct list_head dev_list;
struct sk_buff *gro_list;
struct sk_buff *skb;
};
熟悉老的 NAPI 接口实现的话,里面的字段 poll_list、state、weight、poll、dev、没什么好说的,gro_count 和 gro_list 会在后面讲述 GRO 时候会讲述。需要注意的是,与之前的 NAPI 实现的最大的区别是该结构体不再是 net_device 的一部分,事实上,现在希望网卡驱动自己单独分配与管理 napi 实例,通常将其放在了网卡驱动的私有信息,这样最主要的好处在于,如果驱动愿意,可以创建多个 napi_struct,因为现在越来越多的硬件已经开始支持多接收队列 (multiple receive queues),这样,多个 napi_struct 的实现使得多队列的使用也更加的有效。
与最初的 NAPI 相比较,轮询函数的注册有些变化,现在使用的新接口是:
12
void netif_napi_add(struct net_device *dev, struct napi_struct *napi,
int (*poll)(struct napi_struct *, int), int weight)
熟悉老的 NAPI 接口的话,这个函数也没什么好说的。
值得注意的是,前面的轮询 poll() 方法原型也开始需要一些小小的改变:
1
int (*poll)(struct napi_struct *napi, int budget);
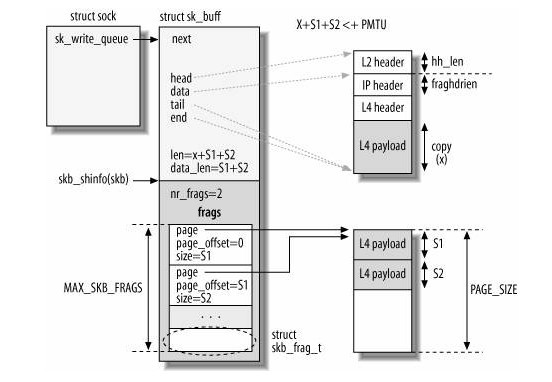
static inline int skb_pagelen(const struct sk_buff *skb)
{
int i, len = 0;
// 我们知道如果设备支持S/G IO的话,nr_frags会包含一些L4 payload,因此我们需要先遍历nr_frags.然后加入它的长度。
for (i = (int)skb_shinfo(skb)->nr_frags - 1; i >= 0; i--)
len += skb_shinfo(skb)->frags[i].size;
// 最后加上skb_headlen,而skb_headlen = skb->len - skb->data_len;因此这里就会返回这个数据包的len。
return len + skb_headlen(skb);
}
int dev_queue_xmit(struct sk_buff *skb)
{
struct net_device *dev = skb->dev;
struct netdev_queue *txq;
struct Qdisc *q;
int rc = -ENOMEM;
/* Disable soft irqs for various locks below. Also
* stops preemption for RCU.
*/
//关闭软中断 - __rcu_read_lock_bh()--->local_bh_disable();
rcu_read_lock_bh();
// 选择一个发送队列,如果设备提供了select_queue回调函数就使用它,否则由内核选择一个队列,这里只是Linux内核多队列的实现,但是要真正的使用都队列,需要网卡支持多队列才可以,一般的网卡都只有一个队列。在调用alloc_etherdev分配net_device是,设置队列的个数
txq = dev_pick_tx(dev, skb);
//从netdev_queue结构上获取设备的qdisc
q = rcu_dereference_bh(txq->qdisc);
#ifdef CONFIG_NET_CLS_ACT
skb->tc_verd = SET_TC_AT(skb->tc_verd, AT_EGRESS);
#endif
//如果硬件设备有队列可以使用,该函数由dev_queue_xmit函数直接调用或由dev_queue_xmit通过qdisc_run函数调用
trace_net_dev_queue(skb);
if (q->enqueue) {
rc = __dev_xmit_skb(skb, q, dev, txq); //使用流控对象发送数据包(包含入队和出队)
//更详细的内容参考说明3
goto out;
}
//下面的处理是在没有发送队列的情况下
/* The device has no queue. Common case for software devices:
loopback, all the sorts of tunnels...
Really, it is unlikely that netif_tx_lock protection is necessary
here. (f.e. loopback and IP tunnels are clean ignoring statistics
counters.)
However, it is possible, that they rely on protection
made by us here.
Check this and shot the lock. It is not prone from deadlocks.
Either shot noqueue qdisc, it is even simpler 8)
*/
//首先,确定设备是开启的,并且还要确定队列是运行的,启动和停止队列有驱动程序决定
//设备没有输出队列典型的是回环设备。这里需要做的就是直接调用dev_start_queue_xmit、、函数,经过驱动发送出去,如果发送失败,就直接丢弃,没有队列可以保存。
if (dev->flags & IFF_UP) {
int cpu = smp_processor_id(); /* ok because BHs are off */
if (txq->xmit_lock_owner != cpu) {
if (__this_cpu_read(xmit_recursion) > RECURSION_LIMIT)
goto recursion_alert;
HARD_TX_LOCK(dev, txq, cpu);
if (!netif_tx_queue_stopped(txq)) {
__this_cpu_inc(xmit_recursion);
rc = dev_hard_start_xmit(skb, dev, txq);//见说明4
__this_cpu_dec(xmit_recursion);
if (dev_xmit_complete(rc)) {
HARD_TX_UNLOCK(dev, txq);
goto out;
}
}
HARD_TX_UNLOCK(dev, txq);
if (net_ratelimit())
printk(KERN_CRIT "Virtual device %s asks to "
"queue packet!\n", dev->name);
} else {
/* Recursion is It is possible,
* unfortunately
*/
recursion_alert:
if (net_ratelimit())
printk(KERN_CRIT "Dead loop on virtual device "
"%s, fix it urgently!\n", dev->name);
}
}
rc = -ENETDOWN;
rcu_read_unlock_bh();
kfree_skb(skb);
return rc;
out:
rcu_read_unlock_bh();
return rc;
}
static inline int __dev_xmit_skb(struct sk_buff *skb, struct Qdisc *q,
struct net_device *dev,
struct netdev_queue *txq)
{
spinlock_t *root_lock = qdisc_lock(q);
bool contended = qdisc_is_running(q);
int rc;
/*
* Heuristic to force contended enqueues to serialize on a
* separate lock before trying to get qdisc main lock.
* This permits __QDISC_STATE_RUNNING owner to get the lock more often
* and dequeue packets faster.
*/
if (unlikely(contended))
spin_lock(&q->busylock);
spin_lock(root_lock);
if (unlikely(test_bit(__QDISC_STATE_DEACTIVATED, &q->state))) {
kfree_skb(skb);
rc = NET_XMIT_DROP;
} else if ((q->flags & TCQ_F_CAN_BYPASS) && !qdisc_qlen(q) &&
qdisc_run_begin(q)) {
/*
* This is a work-conserving queue; there are no old skbs
* waiting to be sent out; and the qdisc is not running -
* xmit the skb directly.
*/
if (!(dev->priv_flags & IFF_XMIT_DST_RELEASE))
skb_dst_force(skb);
__qdisc_update_bstats(q, skb->len);
if (sch_direct_xmit(skb, q, dev, txq, root_lock)) {
if (unlikely(contended)) {
spin_unlock(&q->busylock);
contended = false;
}
__qdisc_run(q);
} else
qdisc_run_end(q);
rc = NET_XMIT_SUCCESS;
} else {
skb_dst_force(skb);
rc = qdisc_enqueue_root(skb, q);
if (qdisc_run_begin(q)) {
if (unlikely(contended)) {
spin_unlock(&q->busylock);
contended = false;
}
__qdisc_run(q);
}
}
spin_unlock(root_lock);
if (unlikely(contended))
spin_unlock(&q->busylock);
return rc;
}
void __qdisc_run(struct Qdisc *q)
{
unsigned long start_time = jiffies;
while (qdisc_restart(q)) { //返回值大于0,说明流控对象非空。
/*
* Postpone processing if
* 1. another process needs the CPU;
* 2. we've been doing it for too long.
*/
if (need_resched() || jiffies != start_time) { //已经不允许继续运行本流控对象。
__netif_schedule(q); //将本队列加入软中断的output_queue链表中。
break;
}
}
qdisc_run_end(q);
}
struct netdev_queue *txq)
{
const struct net_device_ops *ops = dev->netdev_ops;//驱动程序的函数集
int rc = NETDEV_TX_OK;
if (likely(!skb->next)) {
if (!list_empty(&ptype_all))
dev_queue_xmit_nit(skb, dev);//如果dev_add_pack加入的是ETH_P_ALL,那么就会复制一份给你的回调函数。
/*
* If device doesnt need skb->dst, release it right now while
* its hot in this cpu cache
*/
if (dev->priv_flags & IFF_XMIT_DST_RELEASE)
skb_dst_drop(skb);
skb_orphan_try(skb);
if (vlan_tx_tag_present(skb) &&
!(dev->features & NETIF_F_HW_VLAN_TX)) {
skb = __vlan_put_tag(skb, vlan_tx_tag_get(skb));
if (unlikely(!skb))
goto out;
skb->vlan_tci = 0;
}
if (netif_needs_gso(dev, skb)) {
if (unlikely(dev_gso_segment(skb)))
goto out_kfree_skb;
if (skb->next)
goto gso;
} else {
if (skb_needs_linearize(skb, dev) &&
__skb_linearize(skb))
goto out_kfree_skb;
/* If packet is not checksummed and device does not
* support checksumming for this protocol, complete
* checksumming here.
*/
if (skb->ip_summed == CHECKSUM_PARTIAL) {
skb_set_transport_header(skb, skb->csum_start -
skb_headroom(skb));
if (!dev_can_checksum(dev, skb) &&
skb_checksum_help(skb))
goto out_kfree_skb;
}
}
rc = ops->ndo_start_xmit(skb, dev);//调用网卡的驱动程序发送数据。不同的网络设备有不同的发送函数
trace_net_dev_xmit(skb, rc);
if (rc == NETDEV_TX_OK)
txq_trans_update(txq);
return rc;
}
gso:
do {
struct sk_buff *nskb = skb->next;
skb->next = nskb->next;
nskb->next = NULL;
/*
* If device doesnt need nskb->dst, release it right now while
* its hot in this cpu cache
*/
if (dev->priv_flags & IFF_XMIT_DST_RELEASE)
skb_dst_drop(nskb);
rc = ops->ndo_start_xmit(nskb, dev); //调用网卡的驱动程序发送数据。不同的网络设备有不同的发送函数
trace_net_dev_xmit(nskb, rc);
if (unlikely(rc != NETDEV_TX_OK)) {
if (rc & ~NETDEV_TX_MASK)
goto out_kfree_gso_skb;
nskb->next = skb->next;
skb->next = nskb;
return rc;
}
txq_trans_update(txq);
if (unlikely(netif_tx_queue_stopped(txq) && skb->next))
return NETDEV_TX_BUSY;
} while (skb->next);
out_kfree_gso_skb:
if (likely(skb->next == NULL))
skb->destructor = DEV_GSO_CB(skb)->destructor;
out_kfree_skb:
kfree_skb(skb);
out:
return rc;
}