http://blog.chinaunix.net/uid-7295895-id-3076420.html
Linux-2.6.32 NUMA架构之内存和调度
本文将以XLP832通过ICI互连形成的NUMA架构进行分析,主要包括内存管理和调度两方面,参考内核版本2.6.32.9;NUMA架构常见配置选项有:CONFIG_SMP, CONFIG_NUMA, CONFIG_NEED_MULTIPLE_NODES, CONFIG_NODES_SHIFT, CONFIG_SPARSEMEM, CONFIG_CGROUPS, CONFIG_CPUSETS, CONFIG_MIGRATION等。
本文试图从原理上介绍,尽量避免涉及代码的实现细节。
1 NUMA架构简介
NUMA(Non Uniform Memory Access)即非一致内存访问架构,市面上主要有X86_64(JASPER)和MIPS64(XLP)体系。
1.1 概念
NUMA具有多个节点(Node),每个节点可以拥有多个CPU(每个CPU可以具有多个核或线程),节点内使用共有的内存控制器,因此节点的所有内存对于本节点的所有CPU都是等同的,而对于其它节点中的所有CPU都是不同的。节点可分为本地节点(Local Node)、邻居节点(Neighbour Node)和远端节点(Remote Node)三种类型。
本地节点:对于某个节点中的所有CPU,此节点称为本地节点;
邻居节点和远端节点,称作非本地节点(Off Node)。
CPU访问不同类型节点内存的速度是不相同的:本地节点>邻居节点>远端节点。访问本地节点的速度最快,访问远端节点的速度最慢,即访问速度与节点的距离有关,距离越远访问速度越慢,此距离称作Node Distance。
常用的NUMA系统中:硬件设计已保证系统中所有的Cache是一致的(Cache Coherent, ccNUMA);不同类型节点间的Cache同步时间不一样,会导致资源竞争不公平,对于某些特殊的应用,可以考虑使用FIFO Spinlock保证公平性。
1.2 关键信息
1) 物理内存区域与Node号之间的映射关系;
2 XLP832 NUMA初始化
首先需要完成1.2节中描述的3个关键信息的初始化。
2.1 CPU和Node的关系
start_kernel()->setup_arch()->prom_init():
1
2
3
#ifdef CONFIG_NUMA
build_node_cpu_map();
#endif
build_node_cpu_map()函数工作:
a) 确定CPU与Node的相互关系,做法很简单:
1
2
#define cpu_to_node(cpu) (cpu >> 5)
#define cpumask_of_node (NODE_CPU_MASK(node)) /* node0:0~31; node1: 32~63 */
说明:XLP832每个节点有1个物理CPU,每个物理CPU有8个核,每个核有4个超线程,因此每个节点对应32个逻辑CPU,按节点依次展开。另外,实际物理存在的CPU数目是通过DTB传递给内核的;numa_node_id()可以获取当前CPU所处的Node号。
b) 设置每个物理存在的节点的在线状态,具体是通过node_set_online()函数来设置全局变量
nodemask_t node_states[];
这样,类似于CPU号,Node号也就具有如下功能宏:
1
2
for_each_node(node);
for_each_online_node(node);
详细可参考include/linux/nodemask.h
2.2 Node Distance确立
作用:建立buddy时用,可以依此来构建zonelist,以及zone relaim(zone_reclaim_mode)使用,详见后面的4.2.2节。
2.3 内存区域与Node的关系
start_kernel()->setup_arch()->arch_mem_init->bootmem_init()->nlm_numa_bootmem_init():
nlm_get_dram_mapping();
XLP832上电后的默认memory-mapped物理地址空间分布:
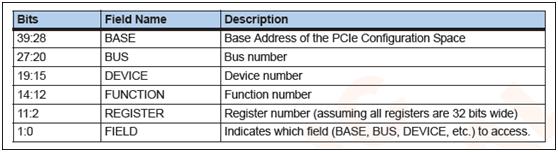
其中PCIE配置空间映射地址范围为[0x1800_0000, 0x1BFF_FFFF],由寄存器ECFG_BASE和ECFG_LIMIT指定(注:但这2个寄存器本身是处于PCIE配置空间之中的)。
PCIE配置空间:
XLP832实现了所有设备都位于虚拟总线0上,每个节点有8个设备,按节点依次排开。
DRAM映射寄存器组:
本小节涉及到的3组不同类型的寄存器(注:按索引对应即DRAM_BAR,DRAM_LIMIT和 DRAM_NODE_TRANSLATION描述一个内存区域属性):
第一组(DRAM空间映射物理空间基址):
1
2
3
4
5
6
7
8
DRAM_BAR0: PCIe Bus 0, Device 0/8/16/24, Function 0, Register 0x54
DRAM_BAR1: PCIe Bus 0, Device 0/8/16/24, Function 0, Register 0x55
DRAM_BAR2: PCIe Bus 0, Device 0/8/16/24, Function 0, Register 0x56
DRAM_BAR3: PCIe Bus 0, Device 0/8/16/24, Function 0, Register 0x57
DRAM_BAR4: PCIe Bus 0, Device 0/8/16/24, Function 0, Register 0x58
DRAM_BAR5: PCIe Bus 0, Device 0/8/16/24, Function 0, Register 0x59
DRAM_BAR6: PCIe Bus 0, Device 0/8/16/24, Function 0, Register 0x5A
DRAM_BAR7: PCIe Bus 0, Device 0/8/16/24, Function 0, Register 0x5B
第二组(DRAM空间映射物理空间长度):
1
2
3
4
5
6
7
8
DRAM_LIMIT0: PCIe Bus 0, Device 0/8/16/24, Function 0, Register 0x5C
DRAM_LIMIT1: PCIe Bus 0, Device 0/8/16/24, Function 0, Register 0x5D
DRAM_LIMIT2: PCIe Bus 0, Device 0/8/16/24, Function 0, Register 0x5E
DRAM_LIMIT3: PCIe Bus 0, Device 0/8/16/24, Function 0, Register 0x5F
DRAM_LIMIT4: PCIe Bus 0, Device 0/8/16/24, Function 0, Register 0x60
DRAM_LIMIT5: PCIe Bus 0, Device 0/8/16/24, Function 0, Register 0x61
DRAM_LIMIT6: PCIe Bus 0, Device 0/8/16/24, Function 0, Register 0x62
DRAM_LIMIT7: PCIe Bus 0, Device 0/8/16/24, Function 0, Register 0x63
第三组(节点相关):
1
2
3
4
5
6
7
8
DRAM_NODE_TRANSLATION0: PCIe Bus 0, Device 0/8/16/24, Function 0, Register 0x64
DRAM_NODE_TRANSLATION1: PCIe Bus 0, Device 0/8/16/24, Function 0, Register 0x65
DRAM_NODE_TRANSLATION2: PCIe Bus 0, Device 0/8/16/24, Function 0, Register 0x66
DRAM_NODE_TRANSLATION3: PCIe Bus 0, Device 0/8/16/24, Function 0, Register 0x67
DRAM_NODE_TRANSLATION4: PCIe Bus 0, Device 0/8/16/24, Function 0, Register 0x68
DRAM_NODE_TRANSLATION5: PCIe Bus 0, Device 0/8/16/24, Function 0, Register 0x69
DRAM_NODE_TRANSLATION6: PCIe Bus 0, Device 0/8/16/24, Function 0, Register 0x6A
DRAM_NODE_TRANSLATION7: PCIe Bus 0, Device 0/8/16/24, Function 0, Register 0x6B
根据上述的PCIE配置空间memory-mapped映射方式便可直接获取寄存器中的值,就可以建立各个节点中的所有内存区域(最多8个区域)信息。关于这些寄存器的使用可以参考“XLP® Processor Family Programming Reference Manual”的“Chapter 7 Memory and I/O Subsystem”。
3 Bootmem初始化
bootmem_init()->…->init_bootmem_node()->init_bootmem_core():
每个节点拥有各自的bootmem管理(code&data之前可以为空闲页面)。
4 Buddy初始化
初始化流程最后会设置全局struct node_active_region early_node_map[]用于初始化Buddy系统,for_each_online_node()遍历所有在线节点调用free_area_init_node()初始化,主要初始化每个zone的大小和所涉及页面的struct page结构(flags中初始化有所属zone和node信息,由set_page_links()函数设置)等。
4.1 NUMA带来的变化
1) pglist_data
1
2
3
4
5
6
7
8
9
10
11
12
13
typedef struct pglist_data {
struct zone node_zones[MAX_NR_ZONES];
struct zonelist node_zonelists[MAX_ZONELISTS];
int nr_zones;
struct bootmem_data *bdata;
unsigned long node_start_pfn;
unsigned long node_present_pages; /* total number of physical pages */
unsigned long node_spanned_pages; /* total size of physical pagerange, including holes */
int node_id;
wait_queue_head_t kswapd_wait;
struct task_struct *kswapd;
int kswapd_max_order;
} pg_data_t;
a)上节的bootmem结构的描述信息存放在NODE_DATA(node)-> bdata中;NODE_DATA(i)宏返回节点i的struct pglist_data结构,需要在架构相关的mmzone.h中实现;
2) zone
1
2
3
4
5
6
7
8
9
10
11
12
struct zone {
#ifdef CONFIG_NUMA
int node;
/*
* zone reclaim becomes active if more unmapped pages exist.
*/
unsigned long min_unmapped_pages;
unsigned long min_slab_pages;
struct per_cpu_pageset *pageset[NR_CPUS];
#else
… …
};
a)最终调用kmalloc_node()为pageset成员在每个CPU的对应的内存节点分配内存;
c) 增加了zone对应的节点号。
4.2 zonelist初始化
本节讲述zonelist的构建方式,实现位于start_kernel()->build_all_zonelists()中,zonelist的组织方式非常关键(这一点与以前的2.6.21内核版本不一样,2.6.32组织得更清晰)。
4.2.1 zonelist order
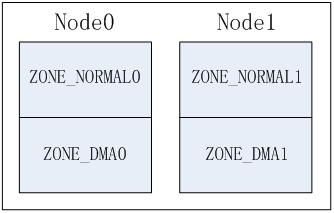
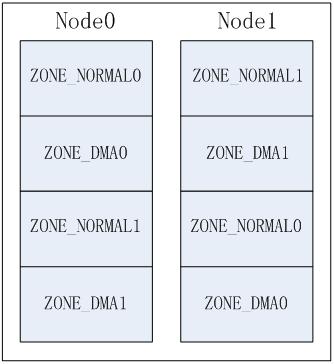
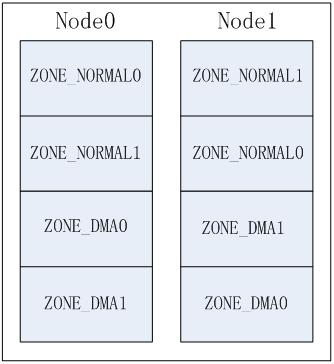
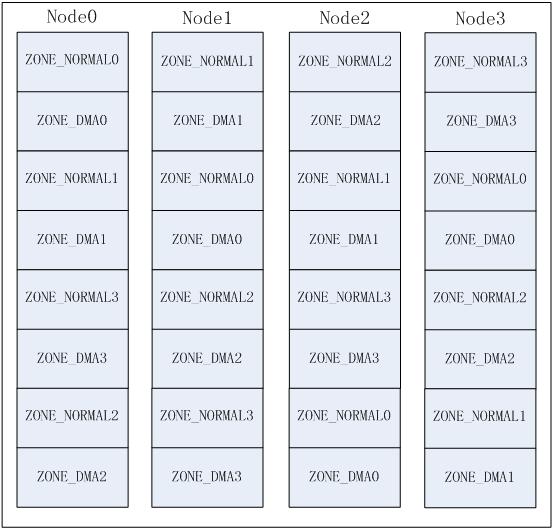
NUMA系统中存在多个节点,每个节点对应一个struct pglist_data结构,此结构中可以包含多个zone,如:ZONE_DMA, ZONE_NORMAL,这样就产生几种排列顺序,以2个节点2个zone为例(zone从高到低排列, ZONE_DMA0表示节点0的ZONE_DMA,其它类似):
a) Legacy方式
b)Node方式
c) Zone方式
可通过启动参数“numa_zonelist_order”来配置zonelist order,内核定义了3种配置:
1
2
3
#define ZONELIST_ORDER_DEFAULT 0 /* 智能选择Node或Zone方式 */
#define ZONELIST_ORDER_NODE 1 /* 对应Node方式 */
#define ZONELIST_ORDER_ZONE 2 /* 对应Zone方式 */
默认配置为ZONELIST_ORDER_DEFAULT,由内核通过一个算法来判断选择Node或Zone方式,算法思想:
a) alloc_pages()分配内存是按照ZONE从高到低的顺序进行的,例如上节“Node方式”的图示中,从ZONE_NORMAL0中分配内存时,ZONE_NORMAL0中无内存时将落入较低的ZONE_DMA0中分配,这样当ZONE_DMA0比较小的时候,很容易将ZONE_DMA0中的内存耗光,这样是很不理智的,因为还有更好的分配方式即从ZONE_NORMAL1中分配;
b) 内核会检测各ZONE的页面数来选择Zone组织方式,当ZONE_DMA很小时,选择ZONELIST_ORDER_DEFAULT时,内核将倾向于选择ZONELIST_ORDER_ZONE方式,否则选择ZONELIST_ORDER_NODE方式。
另外,可以通过/proc/sys/vm/numa_zonelist_order动态改变zonelist order的分配方式。
4.2.2 Node Distance
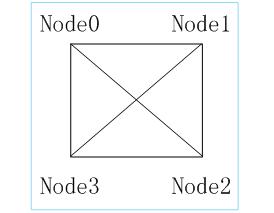
上节中的例子是以2个节点为例,如果有>2个节点存在,就需要考虑不同节点间的距离来安排节点,例如以4个节点2个ZONE为例,各节点的布局(如4个XLP832物理CPU级联)值如下:
上图中,Node0和Node2的Node Distance为25,Node1和Node3的Node Distance为25,其它的Node Distance为15。
4.2.2.1 优先进行Zone Reclaim
另外,当Node Distance超过20的时候,内核会在某个zone分配内存不足的时候,提前激活本zone的内存回收工作,由全局变量zone_reclaim_mode控制,build_zonelists()中:
1
2
3
4
5
6
/*
* If another node is sufficiently far away then it is better
* to reclaim pages in a zone before going off node.
*/
if (distance > RECLAIM_DISTANCE)
zone_reclaim_mode = 1;
通过/proc/sys/vm/zone_reclaim_mode可以动态调整zone_reclaim_mode的值来控制回收模式,含义如下:
1
2
3
4
#define RECLAIM_OFF 0
#define RECLAIM_ZONE (1<<0) /* Run shrink_inactive_list on the zone */
#define RECLAIM_WRITE (1<<1) /* Writeout pages during reclaim */
#define RECLAIM_SWAP (1<<2) /* Swap pages out during reclaim */
4.2.2.2 影响zonelist方式
采用Node方式组织的zonelist为:
即各节点按照与本节点的Node Distance距离大小来排序,以达到更优的内存分配。
4.2.3 zonelist[2]
配置NUMA后,每个节点将关联2个zonelist:
zonelist[1]用来实现仅从节点自身zone中的内存分配(参考__GFP_THISNODE标志)。
5 SLAB初始化
配置NUMA后对SLAB(本文不涉及SLOB或SLUB)的初始化影响不大,只是在分配一些变量采用类似Buddy系统的per_cpu_pageset(单面页缓存)在CPU本地节点进行内存分配。
5.1 NUMA带来的变化
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
struct kmem_cache {
struct array_cache *array[NR_CPUS];
… …
struct kmem_list3 *nodelists[MAX_NUMNODES];
};
struct kmem_list3 {
… …
struct array_cache *shared; /* shared per node */
struct array_cache **alien; /* on other nodes */
… …
};
struct slab {
… …
unsigned short nodeid;
… …
};
上面的4种类型的指针变量在SLAB初始化完毕后将改用kmalloc_node()分配的内存。具体实现请参考enable_cpucache(),此函数最终调用alloc_arraycache()和alloc_kmemlist()来分配这些变量代表的空间。
nodelists[MAX_NUMNODES]存放的是所有节点对应的相关数据,本文称作SLAB节点。每个节点拥有各自的数据;
注:有些非NUMA系统比如非连续内存系统可能根据不同的内存区域定义多个节点(实际上Node Distance都是0即物理内存访问速度相同),所以这些变量并没有采用CONFIG_NUMA宏来控制,本文暂称为NUMA带来的变化。
5.2 SLAB缓存
配置NUMA后,SLAB将有三种类型的缓存:本地缓存(当前CPU的缓存),共享缓存(节点内的缓存)和外部缓存(节点间的缓存)。
SLAB系统分配对象时,先从本地缓存中查找,如果本地缓存为空,则将共享缓存中的缓存搬运本地缓存中,重新从本地缓存中分配;如果共享缓存为空,则从SLAB中进行分配;如果SLAB中已经无空闲对象,则分配新的SLAB后重新分配本地缓存。
SLAB系统释放对象时,先不归还给SLAB (简化分配流程,也可充分利用CPU Cache),如果是同节点的SLAB对象先放入本地缓存中,如果本地缓存溢出(满),则转移一部分(以batch为单位)至共享缓存中;如果是跨节点释放,则先放入外部缓存中,如果外部缓存溢出,则转移一部分至共享缓存中,以供后续分配时使用;如果共享缓存溢出,则调用free_block()函数释放溢出的缓存对象。
关于这三种类型缓存的大小以及参数设置,不在本文的讨论范围。
本地缓存
共享缓存
外部缓存
slab->nodeid记录本SLAB内存块(若干个页面)所在的节点。
示例
例如2个节点,CPU0~31位于Node0,CPU32~CPU63位于Node1:
64个(依次对应于CPU0~CPU63)本地缓存
2个SLAB节点
SLAB节点0(CPU0~CPU31)共享缓存和外部缓存alien[1]sizeof(void )”;
SLAB节点1(CPU32~CPU63)共享缓存和外部缓存alien[0]sizeof(void )”;
另外,可以用内核启动参数“use_alien_caches”来控制是否开启alien缓存:默认值为1,当系统中的节点数目为1时,use_alien_caches初始化为0;use_alien_caches目的是用于某些多节点非连续内存(访问速度相同)的非NUMA系统。
由上可见,随着节点个数的增加,SLAB明显会开销越来越多的缓存,这也是SLUB涎生的一个重要原因。
5.3 __GFP_THISNODE
SLAB在某个节点创建新的SLAB时,都会置__GFP_THISNODE标记向Buddy系统提交页面申请,Buddy系统中看到此标记,选用申请节点的Legacy zonelist[1],仅从申请节点的zone中分配内存,并且不会走内存不足流程,也不会重试或告警,这一点需要引起注意。
SLAB在申请页面的时候会置GFP_THISNODE标记后调用cache_grow()来增长SLAB;
GFP_THISNODE定义如下:
1
2
#ifdef CONFIG_NUMA
#define GFP_THISNODE (__GFP_THISNODE | __GFP_NOWARN | __GFP_NORETRY)
6 调度初始化
配置NUMA后负载均衡会多一层NUMA调度域,根据需要在topology.h中定义,示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
#define SD_NODE_INIT (struct sched_domain) { \
.parent = NULL, \
.child = NULL, \
.groups = NULL, \
.min_interval = 8, \
.max_interval = 32, \
.busy_factor = 32, \
.imbalance_pct = 125, \
.cache_nice_tries = 1, \
.flags = SD_LOAD_BALANCE | SD_BALANCE_EXEC, \
.last_balance = jiffies, \
.balance_interval = 1, \
.nr_balance_failed = 0, \
}
顺便提一下,2.6.32对于实时任务不走负载均衡流程,采用了全局优先级调度的思想,保证实时任务的及时运行;这样的做法同时也解决了低版本内核在处理同一个逻辑CPU上相同最高优先级实时任务的负载均衡的时延。
7 NUMA内存分配
Zonelist[2]组织方式在NUMA内存分配过程中起着至关重要的作用,它决定了整个页面在不同节点间的申请顺序和流程。
7.1显式分配
显式分配即指定节点的分配函数,此类基础分配函数主要有2个:Buddy系统的 alloc_pages_node()和SLAB系统的kmem_cache_alloc_node(),其它的函数都可以从这2个派生出来。
例如,kmalloc_node()最终调用kmem_cache_alloc_node()进行分配。
7.1.1 Buddy显式分配
alloc_pages_node(node, gfp_flags, order)分配流程:__GFP_THISNODE标志,仅在此节点分配内存,使用node节点的Legacy zonelist[1],否则使用其包含所有节点zone的zonelist[0] (见4.2.2.3节);__GFP_HIGHMEM表示最高的zone为ZONE_HIGH;
7.1.2 SLAB显式分配
kmem_cache_alloc_node(cachep, gfp_flags, node)分配流程:
注:fall back行为指的是某个节点上内存不足时会落到此节点的zonelist[0]中定义的其它节点zone分配。
7.1.3 设备驱动
配置CONFIG_NUMA后,设备会关联一个NUMA节点信息,struct device结构中会多一个numa_node字段记录本设备所在的节点,这个结构嵌套在各种类型的驱动中,如struct net_device结构。
1
2
3
4
5
6
7
struct device {
… …
#ifdef CONFIG_NUMA
int numa_node; /* NUMA node this device is close to */
#endif
… …
}
附__netdev_alloc_skb()的实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
struct sk_buff *__netdev_alloc_skb(struct net_device *dev,
unsigned int length, gfp_t gfp_mask)
{
int node = dev->dev.parent ? dev_to_node(dev->dev.parent) : -1;
struct sk_buff *skb;
skb = __alloc_skb(length + NET_SKB_PAD, gfp_mask, 0, node);
if (likely(skb)) {
skb_reserve(skb, NET_SKB_PAD);
skb->dev = dev;
}
return skb;
}
__alloc_skb()最终调用kmem_cache_alloc_node()和kmalloc_node()在此node上分配内存。
7.2 隐式分配和内存策略
隐式分配即不指定节点的分配函数,此类基础分配函数主要有2个:Buddy系统的 alloc_pages()和SLAB系统的kmem_cache_alloc(),其它的函数都可以从这2个派生出来。
隐式分配涉及到NUMA内存策略(Memory Policy),内核定义了四种内存策略。
注:隐式分配还涉及到CPUSET,本文后面会介绍。
7.2.1 内存策略
内核mm/mempolicy.c中实现了NUMA内存的四种内存分配策略:MPOL_DEFAULT, MPOL_PREFERRED, MPOL_INTERLEAVE和MPOL_BIND,内存策略会从父进程继承。
MPOL_DEFAULT:使用本地节点的zonelist;
1)无__GFP_THISNODE申请标记,使用本地节点的zonelist[0];__GFP_THISNODE申请标记,如果本地节点:
MPOL_INTERLEAVE:采用Round-Robin方式从设定的节点集合中选出某个节点,使用此节点的zonelist;
内核实现的内存策略,用struct mempolicy结构来描述:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
struct mempolicy {
atomic_t refcnt;
unsigned short mode; /* See MPOL_* above */
unsigned short flags; /* See set_mempolicy() MPOL_F_* above */
union {
short preferred_node; /* preferred */
nodemask_t nodes; /* interleave/bind */
/* undefined for default */
} v;
union {
nodemask_t cpuset_mems_allowed; /* relative to these nodes */
nodemask_t user_nodemask; /* nodemask passed by user */
} w;
};
成员mode表示使用四种分配策略中的哪一种,联合体v根据不同的分配策略记录相应的分配信息。
另外,MPOL_PREFERRED策略有一种特殊的模式,当其flags置上MPOL_F_LOCAL标志后,将等同于MPOL_DEFAULT策略,内核默认使用此种策略,见全局变量default_policy。
内存策略涉及的分配函数有2个:alloc_pages_current()和alloc_page_vma(),可以分别为不同任务以及任务的不同VMA设置内存策略。
7.2.2 Buddy隐式分配
以默认的NUMA内存策略为例讲解,alloc_pages(gfp_flags, order)分配流程:__GFP_THISNODE标志,仅在此节点分配内存即使用本地节点的Legacy zonelist[1],否则使用zonelist[0] (见4.2.2.3节);__GFP_HIGHMEM表示最高的zone为ZONE_HIGH;
7.2.3 SLAB隐式分配
以默认的NUMA内存策略为例讲解,kmem_cache_alloc(cachep, gfp_flags)分配流程:____cache_alloc()函数在本地节点local_node分配,此函数无fall back行为;____cache_alloc_node(cachep, gfp_flags,local_node)再次尝试在本地节点分配,如果还失败此函数会进行fall back行为;
7.3 小结
上文提到的所有的内存分配函数都允许fall back行为,但有2种情况例外:__GFP_THISNODE分配标记限制了只能从某一个节点上分配内存;
注:还有一种情况,CPUSET限制的内存策略,后面会介绍。
8 CPUSET
CPUSET基于CGROUP的框架构建的子系统,有如下特点:
本节只讲述CPUSET的使用方法和说明。
8.1 创建CPUSET
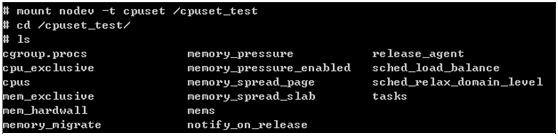
因为CPUSET只能使用/proc文件系统访问,所以第一步就要先mount cpuset文件系统,配置CONFIG_CGROUPS和CONFIG_CPUSETS后/proc/filesystems中将有这个文件系统。
CPUSET是分层次的,可以在cpuset文件系统根目录是最顶层的CPUSET,可以在其下创建CPUSET子项,创建方式很简单即创建一个新的目录。
mount命令:mount nodev –t cpuset /your_dir或mount nodev –t cgroup –o cpuset /your_dir
Mount成功后,进入mount目录,这个就是最顶层的CPUSET了(top_cpuset),下面附一个演示例子:
8.2 CPUSET文件
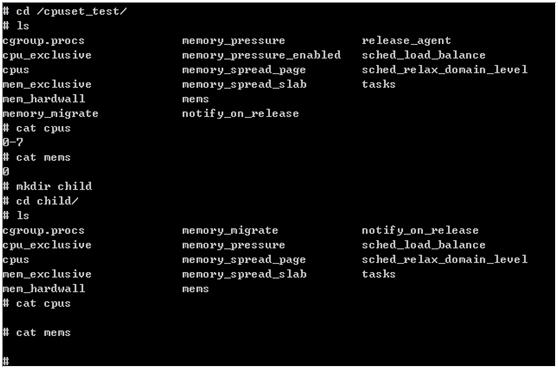
介绍几个重要的CPUSET文件:
2) cgroup.procs是CGROUPS文件,为此CPUSET包含的线程组tgid集合;
3) cpus是CPUSET文件,表示此CPUSET允许的CPU;
4) mems是CPUSET文件,表示此CPUSET允许的内存节点;
echo 0-1 > mems (对应于struct task_struct中的mems_allowed字段)
5) sched_load_balance,为CPUSET文件,设置cpus集合的CPU是否参与负载均衡;
echo 0 > sched_load_balance (禁止负载均衡);默认值为1表示开启负载均衡;
6) sched_relax_domain_level,为CPUSET文件,数值代表某个调度域级别,大于此级别的调度域层次将禁用闲时均衡和唤醒均衡,而其余级别的调度域都开启;
也可以通过启动参数“relax_domain_level”设置,其值含义:
7) mem_exclusive和mem_hardwall,为CPUSET文件,表示内存硬墙标记;默认为0,表示软墙;有关CPUSET的内存硬墙(HardWall)和内存软墙(SoftWall),下文会介绍;
8) memory_spread_page和memory_spread_slab,为CPUSET文件,设定CPUSET中的任务PageCache和SLAB(创建时置有SLAB_MEM_SPREAD)以Round-Robin方式使用内存节点(类似于MPOL_INTERLEAVE);默认为0,表示未开启;struct task_struct结构中增加成员cpuset_mem_spread_rotor记录下次使用的节点号;
9) memory_migrate,为CPUSET文件,表明开启此CPUSET的内存迁移,默认为0;
当一个任务从一个CPUSET1(mems值为0)迁移至另一个CPUSET2(mems值为1)的时候,此任务在节点0上分配的页面内容将迁移至节点1上分配新的页面(将数据同步到新页面),这样就避免了此任务的非本地节点的内存访问。
上图为单Node,8个CPU的系统。
1) 顶层CPUSET包含了系统中的所有CPU以及Node,而且是只读的,不能更改;
8.3 利用CPUSET限定CPU和Node
设置步骤:
这样限定后,此CPUSET中所有的任务都将使用限定的CPU和Node,但毕竟系统中的任务并不能完全孤立,比如还是可能会全局共享Page Cache,动态库等资源,因此内核在某些情况下还是可以允许打破这个限制,如果不允许内核打破这个限制,需要设定CPUSET的内存硬墙标志即mem_exclusive或mem_hardwall置1即可;CPUSET默认是软墙。
硬软墙用于Buddy系统的页面分配,优先级高于内存策略,请参考内核函数:
cpuset_zone_allowed_hardwall()和cpuset_zone_allowed_softwall()
另外,当内核分不到内存将导致Oops的时候,CPUSET所有规则将被打破,毕竟一个系统的正常运行才是最重要的:__GFP_THISNODE标记分配内存的时候(通常是SLAB系统);
8.4 利用CPUSET动态改变调度域结构
利用sched_load_balance文件可以禁用掉某些CPU的负载均衡,同时重新构建调度域,此功能类似启动参数“isolcpus”的功能。
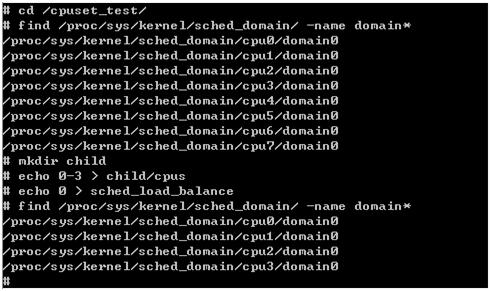
8个CPU的系统中,系统中存在一个物理域,现需要禁掉CPU4~CPU7的负载均衡,配置步骤为:
操作过程见下图:
由图可见,CPU4~CPU7的调度域已经不存在了,具体效果是将CPU4~CPU7从负载均衡中隔离出来。
9 NUMA杂项
1) /sys/devices/system/node/中记录有系统中的所有内存节点信息;/numa_smaps文件信息;
10 参考资料
www.kernel.org
ULK3
XLP® Processor Family Programming Reference Manual