/* to find an entry in a page-table-directory */
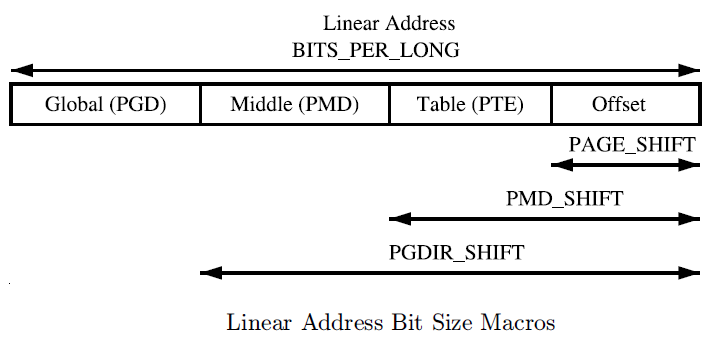
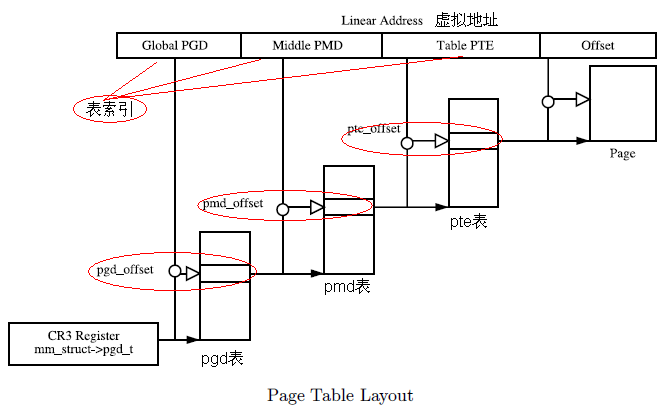
#define pgd_index(addr) ((addr) >> PGDIR_SHIFT) //获得在pgd表中的索引
#define pgd_offset(mm, addr) ((mm)->pgd + pgd_index(addr)) //获得pmd表的起始地址
/* to find an entry in a kernel page-table-directory */
#define pgd_offset_k(addr) pgd_offset(&init_mm, addr)
• pmd_offset
根据通过pgd_offset获取的pgd 项和虚拟地址,获取相关的pmd项(即pte表的起始地址)
12
/* Find an entry in the second-level page table.. */
#define pmd_offset(dir, addr) ((pmd_t *)(dir)) //即为pgd项的值
/**
* follow_page - look up a page descriptor from a user-virtual address
* @vma: vm_area_struct mapping @address
* @address: virtual address to look up
* @flags: flags modifying lookup behaviour
*
* @flags can have FOLL_ flags set, defined in <linux/mm.h>
*
* Returns the mapped (struct page *), %NULL if no mapping exists, or
* an error pointer if there is a mapping to something not represented
* by a page descriptor (see also vm_normal_page()).
*/
struct page *follow_page(struct vm_area_struct *vma, unsigned long address,
unsigned int flags)
{
pgd_t *pgd;
pud_t *pud;
pmd_t *pmd;
pte_t *ptep, pte;
spinlock_t *ptl;
struct page *page;
struct mm_struct *mm = vma->vm_mm;
page = follow_huge_addr(mm, address, flags & FOLL_WRITE);
if (!IS_ERR(page)) {
BUG_ON(flags & FOLL_GET);
goto out;
}
page = NULL;
pgd = pgd_offset(mm, address);
if (pgd_none(*pgd) || unlikely(pgd_bad(*pgd)))
goto no_page_table;
pud = pud_offset(pgd, address);
if (pud_none(*pud))
goto no_page_table;
if (pud_huge(*pud) && vma->vm_flags & VM_HUGETLB) {
BUG_ON(flags & FOLL_GET);
page = follow_huge_pud(mm, address, pud, flags & FOLL_WRITE);
goto out;
}
if (unlikely(pud_bad(*pud)))
goto no_page_table;
pmd = pmd_offset(pud, address);
if (pmd_none(*pmd))
goto no_page_table;
if (pmd_huge(*pmd) && vma->vm_flags & VM_HUGETLB) {
BUG_ON(flags & FOLL_GET);
page = follow_huge_pmd(mm, address, pmd, flags & FOLL_WRITE);
goto out;
}
if (pmd_trans_huge(*pmd)) {
if (flags & FOLL_SPLIT) {
split_huge_page_pmd(mm, pmd);
goto split_fallthrough;
}
spin_lock(&mm->page_table_lock);
if (likely(pmd_trans_huge(*pmd))) {
if (unlikely(pmd_trans_splitting(*pmd))) {
spin_unlock(&mm->page_table_lock);
wait_split_huge_page(vma->anon_vma, pmd);
} else {
page = follow_trans_huge_pmd(mm, address,
pmd, flags);
spin_unlock(&mm->page_table_lock);
goto out;
}
} else
spin_unlock(&mm->page_table_lock);
/* fall through */
}
split_fallthrough:
if (unlikely(pmd_bad(*pmd)))
goto no_page_table;
ptep = pte_offset_map_lock(mm, pmd, address, &ptl);
pte = *ptep;
if (!pte_present(pte))
goto no_page;
if ((flags & FOLL_WRITE) && !pte_write(pte))
goto unlock;
page = vm_normal_page(vma, address, pte);
if (unlikely(!page)) {
if ((flags & FOLL_DUMP) ||
!is_zero_pfn(pte_pfn(pte)))
goto bad_page;
page = pte_page(pte);
}
if (flags & FOLL_GET)
get_page(page);
if (flags & FOLL_TOUCH) {
if ((flags & FOLL_WRITE) &&
!pte_dirty(pte) && !PageDirty(page))
set_page_dirty(page);
/*
* pte_mkyoung() would be more correct here, but atomic care
* is needed to avoid losing the dirty bit: it is easier to use
* mark_page_accessed().
*/
mark_page_accessed(page);
}
if ((flags & FOLL_MLOCK) && (vma->vm_flags & VM_LOCKED)) {
/*
* The preliminary mapping check is mainly to avoid the
* pointless overhead of lock_page on the ZERO_PAGE
* which might bounce very badly if there is contention.
*
* If the page is already locked, we don't need to
* handle it now - vmscan will handle it later if and
* when it attempts to reclaim the page.
*/
if (page->mapping && trylock_page(page)) {
lru_add_drain(); /* push cached pages to LRU */
/*
* Because we lock page here and migration is
* blocked by the pte's page reference, we need
* only check for file-cache page truncation.
*/
if (page->mapping)
mlock_vma_page(page);
unlock_page(page);
}
}
unlock:
pte_unmap_unlock(ptep, ptl);
out:
return page;
bad_page:
pte_unmap_unlock(ptep, ptl);
return ERR_PTR(-EFAULT);
no_page:
pte_unmap_unlock(ptep, ptl);
if (!pte_none(pte))
return page;
no_page_table:
/*
* When core dumping an enormous anonymous area that nobody
* has touched so far, we don't want to allocate unnecessary pages or
* page tables. Return error instead of NULL to skip handle_mm_fault,
* then get_dump_page() will return NULL to leave a hole in the dump.
* But we can only make this optimization where a hole would surely
* be zero-filled if handle_mm_fault() actually did handle it.
*/
if ((flags & FOLL_DUMP) &&
(!vma->vm_ops || !vma->vm_ops->fault))
return ERR_PTR(-EFAULT);
return page;
}
1. First Fit分配器
First Fit分配器是最基本的内存分配器,它使用bitmap而不是空闲块列表来表示内存。在bitmap中,如果page对应位为1,则表示此page已经被分配,为0则表示此page没有被分配。为了分配小于一个page的内存块,First Fit分配器记录了最后被分配的PFN (Page Frame Number)和分配的结束地址在页内的偏移量。随后小的内存分配被Merge到一起并存储到同一页中。
First Fit分配器不会造成严重的内存碎片,但其效率较低,由于内存经常通过线性地址进行search,而First Fit中的小块内存经常在物理内存的开始处,为了分配大块内存而不得不扫描前面大量的内存。
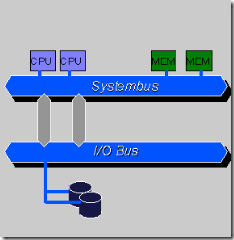
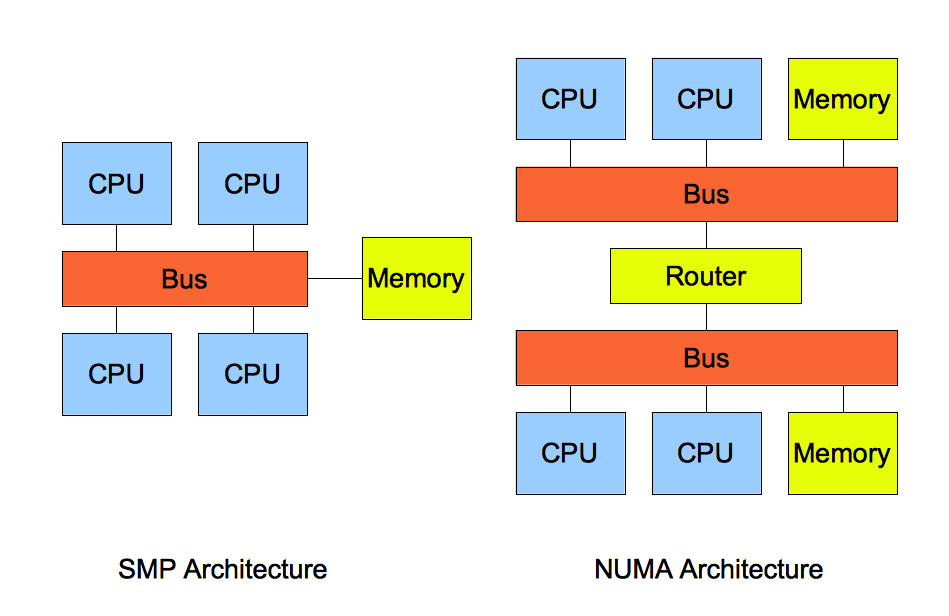
SMP (Symmetric Multi Processing),对称多处理系统内有许多紧耦合多处理器,在这样的系统中,所有的CPU共享全部资源,如总线,内存和I/O系统等,操作系统或管理数据库的复本只有一个,这种系统有一个最大的特点就是共享所有资源。多个CPU之间没有区别,平等地访问内存、外设、一个操作系统。操作系统管理着一个队列,每个处理器依次处理队列中的进程。如果两个处理器同时请求访问一个资源(例如同一段内存地址),由硬件、软件的锁机制去解决资源争用问题。Access to RAM is serialized; this and cache coherency issues causes performance to lag slightly behind the number of additional processors in the system.
所谓对称多处理器结构,是指服务器中多个 CPU 对称工作,无主次或从属关系。各 CPU 共享相同的物理内存,每个 CPU 访问内存中的任何地址所需时间是相同的,因此 SMP 也被称为一致存储器访问结构 (UMA : Uniform Memory Access) 。对 SMP 服务器进行扩展的方式包括增加内存、使用更快的 CPU 、增加 CPU 、扩充 I/O( 槽口数与总线数 ) 以及添加更多的外部设备 ( 通常是磁盘存储 ) 。
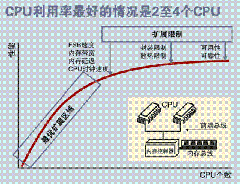
SMP 服务器的主要特征是共享,系统中所有资源 (CPU 、内存、 I/O 等 ) 都是共享的。也正是由于这种特征,导致了 SMP 服务器的主要问题,那就是它的扩展能力非常有限。对于 SMP 服务器而言,每一个共享的环节都可能造成 SMP 服务器扩展时的瓶颈,而最受限制的则是内存。由于每个 CPU 必须通过相同的内存总线访问相同的内存资源,因此随着 CPU 数量的增加,内存访问冲突将迅速增加,最终会造成 CPU 资源的浪费,使 CPU 性能的有效性大大降低。实验证明, SMP 服务器 CPU 利用率最好的情况是 2 至 4 个 CPU 。
2. NUMA(Non-Uniform Memory Access)
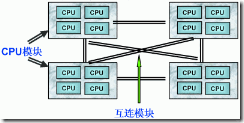
由于 SMP 在扩展能力上的限制,人们开始探究如何进行有效地扩展从而构建大型系统的技术, NUMA 就是这种努力下的结果之一。利用 NUMA 技术,可以把几十个 CPU( 甚至上百个 CPU) 组合在一个服务器内。其 CPU 模块结构如图 2 所示:
图 2.NUMA 服务器 CPU 模块结构
NUMA 服务器的基本特征是具有多个 CPU 模块,每个 CPU 模块由多个 CPU( 如 4 个 ) 组成,并且具有独立的本地内存、 I/O 槽口等。由于其节点之间可以通过互联模块 ( 如称为 Crossbar Switch) 进行连接和信息交互,因此每个 CPU 可以访问整个系统的内存 ( 这是 NUMA 系统与 MPP 系统的重要差别 ) 。显然,访问本地内存的速度将远远高于访问远地内存 ( 系统内其它节点的内存 ) 的速度,这也是非一致存储访问 NUMA 的由来。由于这个特点,为了更好地发挥系统性能,开发应用程序时需要尽量减少不同 CPU 模块之间的信息交互。
利用 NUMA 技术,可以较好地解决原来 SMP 系统的扩展问题,在一个物理服务器内可以支持上百个 CPU 。比较典型的 NUMA 服务器的例子包括 HP 的 Superdome 、 SUN15K 、 IBMp690 等。
但 NUMA 技术同样有一定缺陷,由于访问远地内存的延时远远超过本地内存,因此当 CPU 数量增加时,系统性能无法线性增加。如 HP 公司发布 Superdome 服务器时,曾公布了它与 HP 其它 UNIX 服务器的相对性能值,结果发现, 64 路 CPU 的 Superdome (NUMA 结构 ) 的相对性能值是 20 ,而 8 路 N4000( 共享的 SMP 结构 ) 的相对性能值是 6.3 。从这个结果可以看到, 8 倍数量的 CPU 换来的只是 3 倍性能的提升。
248 struct tss_struct {
249 /*
250 * The hardware state:
251 */
252 struct x86_hw_tss x86_tss;
253
254 /*
255 * The extra 1 is there because the CPU will access an
256 * additional byte beyond the end of the IO permission
257 * bitmap. The extra byte must be all 1 bits, and must
258 * be within the limit.
259 */
260 unsigned long io_bitmap[IO_BITMAP_LONGS + 1];
261
262 /*
263 * .. and then another 0x100 bytes for the emergency kernel stack:
264 */
265 unsigned long stack[64];
266
267 } ____cacheline_aligned;
190#ifdef CONFIG_X86_32
191 /* This is the TSS defined by the hardware. */
192 struct x86_hw_tss {
193 unsigned short back_link, __blh;
194 unsigned long sp0; //当前进程的内核栈顶指针
195 unsigned short ss0, __ss0h; //当前进程的内核栈段描述符
196 unsigned long sp1;
197 /* ss1 caches MSR_IA32_SYSENTER_CS: */
198 unsigned short ss1, __ss1h;
199 unsigned long sp2;
200 unsigned short ss2, __ss2h;
201 unsigned long __cr3;
202 unsigned long ip;
203 unsigned long flags;
204 unsigned long ax;
205 unsigned long cx;
206 unsigned long dx;
207 unsigned long bx;
208 unsigned long sp; //当前进程用户态栈顶指针
209 unsigned long bp;
210 unsigned long si;
211 unsigned long di;
212 unsigned short es, __esh;
213 unsigned short cs, __csh;
214 unsigned short ss, __ssh;
215 unsigned short ds, __dsh;
216 unsigned short fs, __fsh;
217 unsigned short gs, __gsh;
218 unsigned short ldt, __ldth;
219 unsigned short trace;
220 unsigned short io_bitmap_base;
221
222 } __attribute__((packed));
35 * per-CPU TSS segments. Threads are completely 'soft' on Linux,
36 * no more per-task TSS's. The TSS size is kept cacheline-aligned
37 * so they are allowed to end up in the .data..cacheline_aligned
38 * section. Since TSS's are completely CPU-local, we want them
39 * on exact cacheline boundaries, to eliminate cacheline ping-pong.
40 */
41 DEFINE_PER_CPU_SHARED_ALIGNED(struct tss_struct, init_tss) = INIT_TSS;