http://blog.csdn.net/cybertan/article/details/5686451
调度
公平调度 (fair-share scheduling) 的进程调度算法:
一、公平分享的调度策略
Linux 的调度算法是相对独立的一个模块,而且较容易理解。因此很多系统高手都爱对调度算法做改进。但是可以说调度器是一个非常神秘,难以捉摸的精灵。可能通过改变一个关键参数你就可以大大提高系统的效率。
对于一般进程, CPU 的使用时间都是系统平均分配给每一个进程的,因此这种公平分享都是从 进程的角度 出发的。 Bach 在 1986 年提出了公平分享调度策略( Fair_Share scheduling )来解决这个问题。和 Linux 三种内建策略比,公平分享调度策略是一种更抽象的调度策略。它认为 CPU 应该根据拥有进程的组(对 Linux 来说是用户)来分配时间,它实现了从 用户角度 考虑的公平原则。
由内核的结构来看,实现这个算法有很多种方式。我们可以在与调度相关的程序里做小小的改动来实现,如改动一些数据结构并改写 schedule() 函数。当然也可以做得很复杂,比如重写 schedule() 来实现所需要的结果。但是有一点我们是要必须牢记的,那就是大部分的 Linux 核心都是以短小高效为最高目标。所以,改进的算法必须尽量向这个目标靠拢。
二、新调度策略的实现:分析
1 、这里所说的 ‘ 组 ’ 的概念,在 Linux 中是一个用户。我们所关心的是 Linux 的用户,而不是 UNIX 系统下的用户组或是别的什么概念。因此 在公平共享调度策略中,一个进程能够分配到的时间与登录的系统用户数以及拥有该进程用户开辟进程数的多少有关。
2 、超级用户的进程是 独立于公平分享算法 的,因此它拥有的进程得到的调度时间应该和现在的进程调度算法分配时间相当。
3 、对于实时进程,调度算法仍旧给予比普通进程更高的优先权。不过也不用担心会花太多的时间去实现,只要在现在调度算法的基础上稍做改进就可以简单实现。
4 、新的调度算法对系统的吞吐量不能有太多的影响。比如说,如果定义的时间片少于 2 个 “ 滴答 ” ,那么新实现的调度器效率将变得很差。因为过于频繁的进程切换将耗费大部分的系统时间,而真正用于程序计算的时间则排在第二位了。 此条说明时间片的划分不能太小。
5 、我们所实现的算法并不需要绝对的公平,严格的平均是需要用效率为代价来换取的。如果算法过于精确,那就需要复杂的数据结构和耗时的计算过程,所以我们可以在以速度为第一原则的基础上实现 “ 模糊 ” 的公平分享。
6 、我们首先需要的是不断地思考和设计,只有将所有的问题都考虑清楚以后才可以开始动手。调度器是操作系统的核心,它将被频繁调用,因此其作用和影响也将是巨大的。我们要花费最小的代价实现算法,并且这种改动对系统核心的影响要降到最小。
Linux 的进程调度机制:
概述:
在多进程的操作系统中,进程调度是一个全局性的、关键性的问题。可以说,关于进程调度的研究是整个操作系统理论的核心,它对系统的总体设计、系统的实现、功能设置以及各方面的性能都有着决定性的影响。
1、 150ms :当系统中有大量进程共存时,根据测定,当每个用户可以接受的相应速度延迟超过150 ms 时,使用者就会明显地感觉到了。
2、 在设计一个进程调度机制时要考虑的具体问题主要有:
调度的时机:什么情况下、什么时候进行调度;
调度的政策:根据什么准则挑选下一个进入运行的进程;
调度的方式:是 “ 可剥夺 ” 还是 “ 不可剥夺 ” 。当正在运行的进程并不自愿暂时放弃对CPU的使用权时,是否可以强制性地暂时剥夺其使用权,停止其运行而给其他进程一个机会。如果是可剥夺的,那么是否在任何条件下都可剥夺,有没有例外?
3、linux 内核的调度机制:
1)调度的时机:
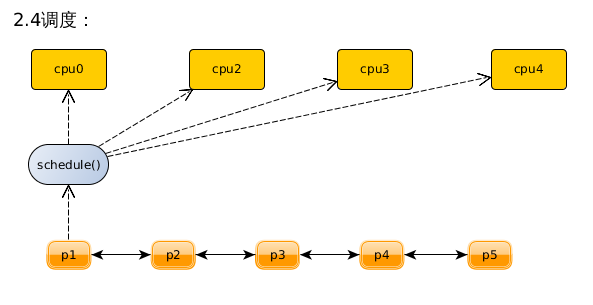
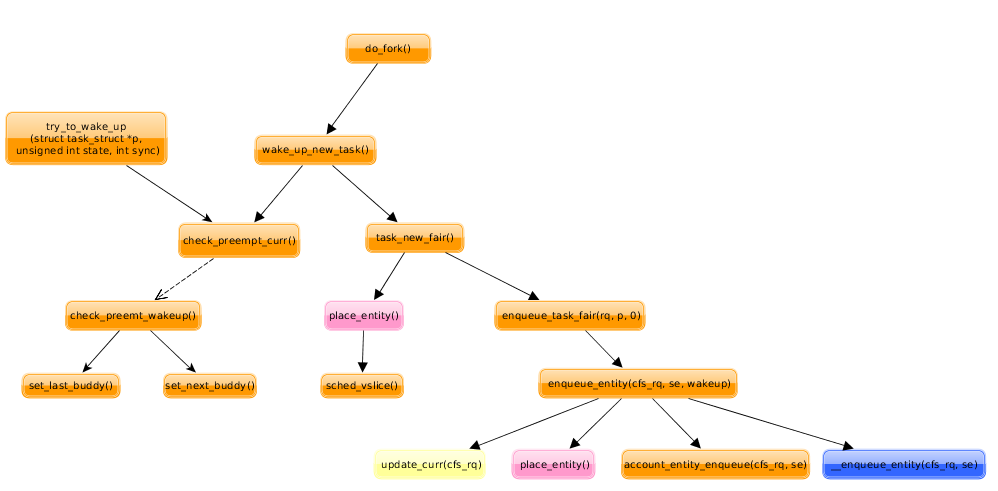
- 首先,自愿的调度 ( 主动调度 ) 随时都可以进行:在内核里面,一个进程可以通过 schedule() 启动一次调度。也就是由当前进程自愿调用 schedule() 暂时放弃运行的情景。
- 除此之外,调度还可以非自愿的,即强制地发生在每次从系统调用返回的前夕,以及每次从中断或者异常处理 返回到用户空间 的前夕。
上述红字说明:只有在用户空间(当CPU在用户空间运行时)发生的中断或者异常才会引起调度。
1 2 3 4 5 6 7 8 9 10 11 12 | |
从上述代码中 (arch/i386/kernel/entry.S) ,可以看出,转入 ret_with_reschedule 的条件为中断或异常发生前 CPU 的运行级别为3,即用户态。
这一点 ( 只有在用户空间发生的中断或者异常才会引起调度 ) 对于系统的设计和实现有很重要的意义:因为这意味着当 CPU 在内核中运行时无需考虑强制调度的可能性。发生在系统空间中的中断或异常当然是可能的,但是这种中断或者异常不会引起调度。这使得内核的实现简化了,早期的 Unix 内核正是靠这个前提来简化其设计与实现的。否则的话,内核中所有可能为一个以上进程共享的变量和数据结构就全都要通过互斥机制 ( 如信号量 ) 加以保护,或者说放在临界区里面。即在内核中由于不会发生调度而无需考虑互斥。但是在多处理器 SMP 系统中,这种简化正在失去重要性:因为我们不得不考虑在另一个处理器上运行的进程访问共享资源的可能性。这样,不管在同一个 CPU 上是否可能在内核中发生调度,所有可能为多个进程 ( 可能在不同的 CPU 上运行 ) 共享的变量和数据结构,都得保护起来。这就是为什么读者在阅读代码时看到那么多的 up() 、 down() 等信号量操作或者加锁操作的原因。
注意: “ 从系统空间返回到用户空间 ” 只是发生调度的必要条件,而不是充分条件。也就是说,这个条件满足了,调度并不是一定会发生的,具体是否发生调度还要判断当前进程的 task_struct 结构中的 need_resched 成员是否为非0,非0时才会转到 reschedule 处调用 schedule():
1 2 3 4 5 6 7 8 9 | |
need_resched 成员是内核设置的,因为在用户空间是访问不到进程的 task_struct 结构的。除了当前进程通过系统调用自愿让出运行以及在系统调用中因某种原因受阻以外,主要就是当因某种原因唤醒一个进程的时候,以及在时钟中断服务程序发现当前进程已经连续运行太久的时候,内核会对 need_resched 成员进行设置 ( 非0 ) ,以重新调度。
2)调度的方式:
Linux 内核的调度方式可以说是 “ 有条件的可剥夺 ” 方式。 *当进程在用户空间运行时,无论自愿不自愿,一旦有必要 ( 例如该进程已经运行了足够长的时间 ) ,内核就可以暂时剥夺其运行而调度其他进程进入运行。
*但是,一旦进程进入了内核空间,或者说进入 “ 系统态 ” 。这时候,尽管内核知道应该要调度了,但是实际上调度并不会发生,直到该进程即将 “ 下台 ” ,也就是 回到用户空间的前夕 才能剥夺其运行权力。所以, linux 的调度方式从原则上来说是可剥夺的,可是实际上由于调度时机的限制而变成了有条件的。
3)调度策略:
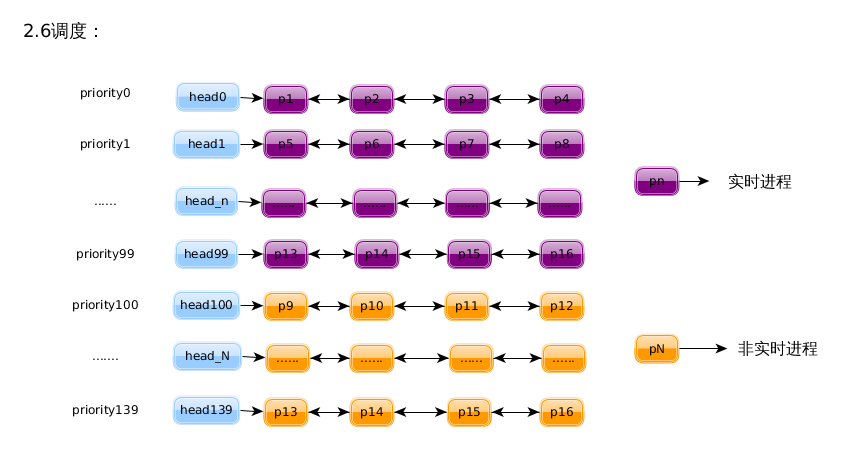
基本上是从 UNIX 继承下来的 以优先级为基础 的调度。内核为系统中的每个进程计算出一个反映其运行 “ 资格 ” 的权值,然后挑选权值最高的进程投入运行。在运行的过程中,当前进程的资格 ( 权值 ) 随时间而递减,从而在下一次调度的时候原来资格较低的进程可能就更有资格运行了。到所有的进程的资格都变为0时,就重新计算一次所有进程的资格。
但是,为了适应各种不同应用的需要,内核 在此基础上 实现了三种不同的策略: SCHED_FIFO 、 SCHED_RR 、 SCHED_OTHER 。每个进程都有自己适用的调度策略,并且,进程还可以通过系统调用 sched_setscheduler() 设定自己适用的调度策略。下面介绍一下他们的区别:
SCHED_FIFO :适用于时间性要求比较强,但每次运行所需的时间比较短的进程,因此多用于实时进程;
SCHED_RR:RR 表示 Round Robin ,是轮流的意思 ( 轮换调度 ) ,这种策略适合比较大、也就是每次运行时间较长的程序。使用 SCHED_RR 策略地进程在 schedule() 调度中有一点特殊的处理。
上两者的比较: SCHED_FIFO 、 SCHED_RR 都是基于优先级的调度策略,可是在怎样调度具有相同优先级的进程的问题上两者有区别:
调度策略为 SCHED_FIFO 的进程一旦受到调度而开始运行之后,就要一直运行到自愿让出或者被优先级更高的进程剥夺为止。对于每次受到调度时要求运行时间不长的进程,这样并不会有多大的影响。可是, 如果是受到调度后可能执行很长时间的进程 ,这样就不公平了。这种不公正性是对具有相同优先级的进程而言的,同级的进程必须等待该进程自愿让出或者直到其运行结束。因为具有更高优先级的进程可以剥夺他的运行,而优先级则本来就没有机会运行,谈不上不公正。
所以,对于执行时间可能会很长的进程来说,应该使用 SCHED_RR 调度策略,这种策略 在相同的优先级的进程上实行轮换调度。 也就是说:对调度策略为 SCHED_RR 的进程有个时间配额,用完这个配额就要让具有相同优先级的其他就绪进程先运行。看 schedule() 的540行对调度策略为 SCHED_RR 的当前进程的处理。
SCHED_OTHER :是传统的调度策略,比较适合于交互式的分时应用。
问题:既然每个进程都有自己的适用的调度策略,内核怎样来调用使用不同调度策略的进程的呢?是根据什么挑选出下一个要运行的进程呢?
实际上,挑选的原则最后还是归结到每个进程的权值,只不过是在计算资格的时候将适用的策略也考虑进去了,就好像考大学时符合某些特殊条件的考生会获得加分一样。同时,对于适用不同策略地进程的优先级别也加了限制。
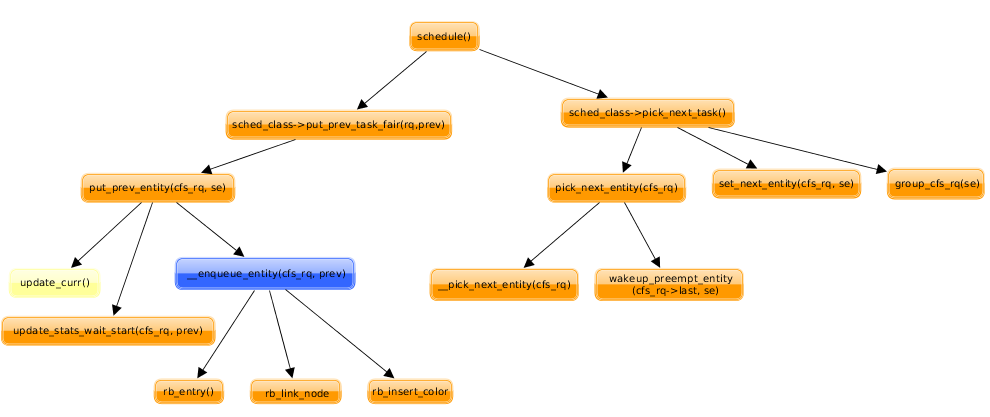
4、调度程序 schedule() :
调度程序 schedule() 是一个非常频繁地执行的函数,因此要将运行效率放在第一位,函数中使用了很多的 goto 语句。
前面讲过,对 schedule() 只能由进程在内核中主动 调用,或者在当前进程从系统空间返回用户空间的前夕被动的 发生,而不能在一个中断服务程序的内部发生。即使一个中断服务程序有调度的要求,也只能通过把当前进程的 need_resched 字段设为1来表达这种要求,而不能直接调用 schedule() 。所以,如果在某个中断服务程序内部调用了 schedule() ,那一定是有问题的,所以转向 scheduling_in_interrupt.(kernel/sched.c)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | |
我们来看一下内核对这种问题的响应:
1 2 3 4 5 | |
内核对此的响应是显示或者在 /var/log/messages 文件末尾添上一条出错信息,然后执行一个宏操作 BUG 。
接着往下看 schedule() :
如果有内核软中断服务请求在等待,那么就转入 handle_softirq :
1 2 3 4 | |
执行 softirq 队列完毕以后继续往下看:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | |
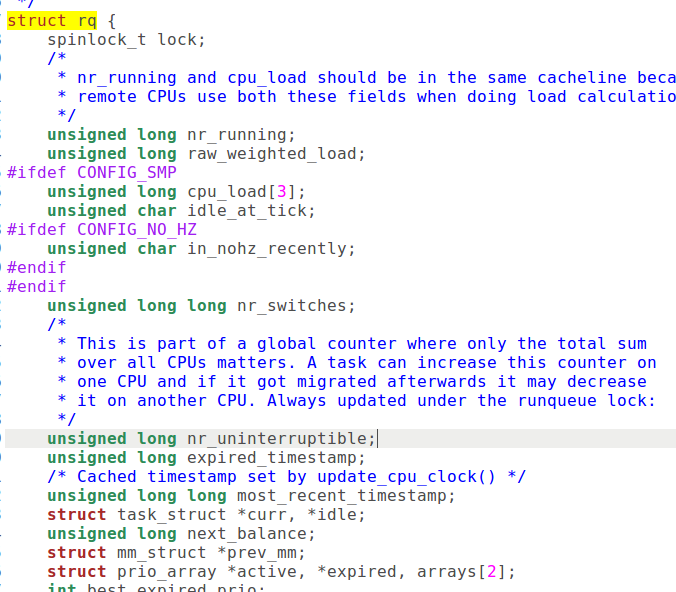
指针 sched_data 指向一个 schedule_data 数据结构,用来保存供下一次调度时使用的信息。此数据结构的定义如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
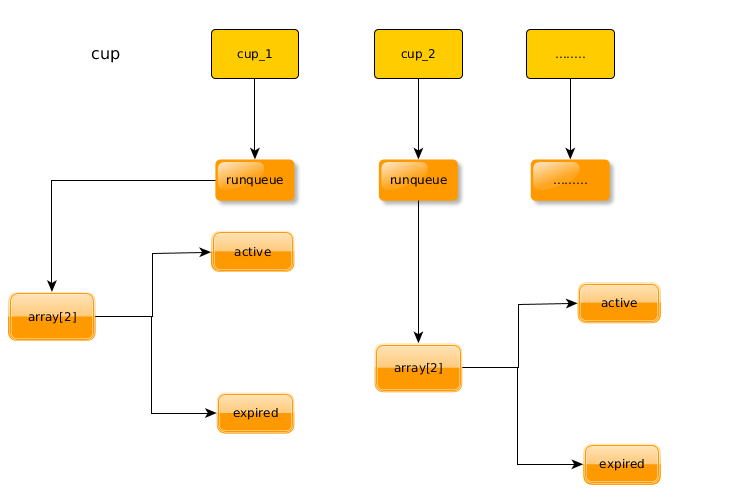
这里的 cycles_t 实际上是无符号整数,用来记录调度发生的时间。这个数据结构是为多处理器 SMP 结构而设的,因此我们不必关心。数组中的第一个元素,即 CPU0 的 schedule_data 结构初始化为 {&init_task,0} ,其余的则全为{0,0}。代码中的 __cacheline_aligned 表示数据结构的起点应与高速缓存中的缓冲线对齐。
下面就要涉及可执行进程队列了,所以先将这个队列锁住 (536 行 ) ,以防止其他处理器的干扰。从 538 行开始:如果当前进程 prev 的调度策略是 SCHED_RR ,也就是轮换调度,那就要先进行一点特殊的处理 ( 540 : goto move_rr_last; ) 。 (对使用 SCHED_RR 策略的当前进程的处理)
1 2 3 4 5 6 7 8 | |
这里的 prev>counter :代表这当前进程的运行时间配额,其数值在每次时钟中断时都要递减 (update_process_times() 中实现的 ) 。因此,不管一个进程的时间配额有多高,随着运行时间的积累最终总会递减到0。对于调度策略为 SCHED_RR 的进程,一旦其时间配额降到0,就要从 可执行进程队列 runqueue 中当前的位置上移动到队列的末尾,同时恢复其最初的时间配额( NICE_TO_TICKS ),以等待下一次的调度。对于具有相同优先级的进程,调度的时候排在前面的进程优先,所以这使队列中具有相同优先级的其他进程有了优势。
宏操作 NICE_TO_TICKS 根据系统时钟的精度将进程的优先级别换算成可以运行的时间配额。在 kernel/sched.c 中定义。
将一个进程的 task_struct 结构从可执行队列中的当前位置移到队列的末尾是由 move_last_runqueue() 完成的 (kernel/sched.c) 。把进程移到可执行进程队列的末尾意味着:如果队列中没有资格更高的进程,但是有一个资格与之相同的进程存在,那么,这个资格虽然相同而排在前面的进程会被选中。
继续看 schedule() :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | |
当前进程,就是正在执行的进程,当进入 schedule() 时其状态却不一定是 TASK_RUNNING 。例如:当前进程如已经在 do_exit() 中将其状态改成 TASK_ZOMBIE ,又如当前进程在 sys_wait4() 中调用 schedule() 时的状态为 TASK_INTERRUPTIBLE 。所以,这里的 prev>state 与其说是当前进程的状态不如说是其意愿。当其意愿既不是继续执行也不是可中断的睡眠时,就要通过 del_from_runqueue() 把这个进程从可执行队列中撤下来。另一方面, 也可以看出 TASK_INTERRUPTIBLE 和 TASK_UNINTERRUPTIBLE 两种睡眠状态之间的区别: 前者在进程有信号等待处理时要将其改成 TASK_RUNNING ,让其处理完这些信号再说,而后者则不受信号的影响。
最后,将 prev>need_resched 恢复为0,因为所需求的调度已经在进行了。 下面的任务就是要 挑选出一个进程来运行了 ( 这一部分是很重要的,通过对就绪进程队列进行扫描 ) 。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | |
在这段程序中, next 总是指向已知最佳的候选进程, c 则是这个进程的综合权值,或者是运行资格。
挑选的过程是从 idle 进程即 0 号进程开始,其权值为- 1000 ,这是可能的最低值,表示仅在没有其他进程可以运行时才会让他运行。
然后,遍历可执行队列 runqueue 中的每个进程 ( 在单 CPU 系统中 can_schedule() 的返回值永远是 1) ,也就是一般操作系统书中所称的就绪进程。为每一个就绪进程通过函数 goodness () 计算出他当前所具有的权值,然后与当前的最高值 c 相比。注意这里的条件: weight > c , 这意味着 “ 先入为大 ” 。也就是说,如果两个进程有相同的权值的话,排在队列前面的进程胜出,优先运行。
这里还有一个小插曲:如果当前进程的意图是继续运行,那么就要先执行一下 still_running(kernel/sched.c) :
1 2 3 4 5 6 7 | |
也就是说,如果当前进程想要继续运行,那么在挑选候选进程时以当前进程此刻的权值开始比较。而且这意味着,对于具有相同权值的其他进程来说,当前进程优先。
那么,进程的当前权值是怎样计算的呢?也就是 goodness() 是怎样执行的呢?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 | |
*首先,如果一个进程通过系统调用 sched_yield() 明确表示了 “ 礼让 ” 后,就将其权值定位 -1 。这是很低的权值,一般就绪进程的权值至少是 0 。
*对于没有实时要求的进程 ,即调度策略为 SCHED_OTHER 的进程,其权值主要取决于两个因素:一个是剩下的时间配额 p->counter ,如果用完了则权值为 0 。另一个是进程的优先级 nice ,这是从早期 Unix 沿用下来的负向优先级 ( 越负,优先级越高 ) ,其取值范围为 19~-20 ,只有特权用户才能把 nice 值设置为小于 0 。所以,综合的权值 weight 在时间配额尚未用完时基本上是二者之和。 此外,如果是内核线程,或者其用户 空间与当前进程的相同,因而无需切换用户空间,则会得到一点小 “ 奖励 ” ,将权值额外加 1 。
*对于实时进程,即调度策略为 SCHED_FIFO 或者 SCHED_RR 的进程,则另有一种正向的优先级 ,那就是实时优先级 rt_priority ,而权值为 1000 + p->rt_priority 。可见, SCHED_FIFO 或者 SCHED_RR 两种有时间要求的策略赋予进程很高的权值 ( 相对于 SCHED_OTHER) 。这种进程的权值至少是 1000 。另一方面, rt_priority 的值对于实时进程之间的权值比较也起着重要的作用,其数值也是在 sched_setscheduler() 中与调度策略一起设置的。
从上面可以看出:对于这两种实时调度策略,一个进程已经运行了多久,即时间配额 p->counter 的当前值,对权值的计算不起所用。不过,前面讲到,对于使用 SCHED_RR 策略地进程,当 p->counter 达到 0 时会导致将进程移到队列尾部。
实时进程的 nice 数值与优先级无关,但是对 使用 SCHED_RR 策略地进程的时间配额大小有关 ( 宏操作 NICE_TO_TICKS()) 。由于实时进程的权值有个很大的基数 (1000) ,因此当有实时进程就绪时,非实时进程是没有机会运行的。
由此可见, linux 内核中对权值的计算是很简单的,但是 goodness() 函数并不代表 linux 调度算法的全部,而要与前面讲到的 对 SCHED_RR 进程的特殊处理 、 对意欲继续运行的当前进程的特殊处理 ‘ 以及下面要讲到的 recalculate 结合起来分析。
上面 still_running_back 运行结束后,变量 c 的值有几种可能:一种可能是一个大于 0 的正数,此时 next 指向挑选出来的进程;另一种可能是 c 的值为 0 ,发生于就绪队列中所有进程的权值都是 0 的时候。由于除了 init 进程和调用了 sched_yield() 的进程以外,每个进程的权值最低为 0 ,所以只要队列中有其他就绪进程存在就不可能为负数。因此,队列中所有其他进程的权值都已经降到 0 了,说明这些进程的调度策略都是 SCHED_OTHER ,即系统中当前没有就绪的实时进程,因为如果有策略为 SCHED_FIFO 或者 SCHED_RR 的进程存在,其权值至少也有 1000 。
let`s go on :回到 schedule()
1 2 3 4 5 6 | |
如果当前已经选择的进程(权值最高的进程)的权值为 0 ,那就要重新计算各个进程的时间配额。如上所述,这说明系统中当前没有就绪的实时进程。而且,这种情况已经持续了一段时间,否则 SCHED_OTHER 进程的权值就没有机会消耗到 0 。
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
这里所作的运算是将每个进程的当前的时间配额 p->counter 除以 2 ,再在上面加上由该进程的 nice 值换算过来的 tick 数量。宏操作 NICE_TO_TICKS 的定义在前面已经见过,显然 nice 值对于非实时进程既表示优先级也决定着时间配额。
注意:这里的 for_each_task() 是对所有进程的循环,而并不是仅对就绪进程队列的循环,对于不再就绪进程队列中的非实时进程 ,这里得到了提升其时间配额、从而提升其综合权值的机会。不过,这种对综合权值的提升是很有限的,每次重新计算都将原有的时间配额减半,再与 NICE_TO_TICKS(p->nice) 相加,这样就决定了重新计算以后的综合权值永远也不可能达到 NICE_TO_TICKS(p->nice) 的两倍。因此,即使经过很长时间的韬光养晦,也不可能达到可与实时进程竞争的地步,所以只是对非实时进程之间的竞争有意义。
至于实时进程,时间配额的增加并不会提升其综合权值,而且对于 SCHED_FIFO 进程,时间配额就没有什么意义。
重新计算完权值以后,程序转回 repeat_schedule( 跳回前面,再次执行挑选进程 ) 处重新挑选。这样,当再次完成对就绪进程队列的扫描时,变量 c 的值就应该不为 0 了,此时 next 指向挑选出来的进程。
至此,已经挑选好进程了(权值最高的进程)。
还没有结束阿?哈哈
进程挑好之后,接下来要做的就是切换的事情了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 | |
跳过对 SMP 结构的条件编译部分。
首先,如果挑选出来的进程 next 就是当前进程 prev ,就不用切换,直接跳转到 same_process 处就返回了。这里的 reacquire_kernel_lock() 对于 i386 单 CPU 结构而言是空语句。前面已经把当前进程的 need_resched 清 0 ,如果现在又成了非 0 ,则一定是发生了中断并且情况有了变化,所以转回 need_resched_back 再调度一次。
否则,如果挑选出来的进程 next 与当前进程 prev 不同,那就要切换了。对于 i386 单 CPU 结构而言, prepare_to_switch() 也是空语句。而 649 行的 __schedule_tail() 则只是将当前进程 prev 的 task_struct 结构中的 policy 字段里的 SCHED_YIELD 标志位清成 0 。所以实际上只剩下了两件事:对用户虚存空间的处理;进程的切换 switch_to() 。
实验:
第二部分:如何在 sched.c 中实现算法?
首先,确定何时进行算法的计算过程。 是在 schedule() 中选择下一运行进程之前?
选择下一运行进程时?选择下一运行进程之后?还是直接修改 goodness() 函数以确定下一运行进程呢?
在以上提到的各个位置都可以添加代码实现我们的算法,但是考虑到 schedule() 函数是被频繁调用的一个函数 ,它的运行效率直接影响到了系统的吞吐量,因此我们所添加的代码段应该是被调用的频率越小越好。
在这种原则的指导之下,我们发现有一段代码只有在 CPU 的时间段( epoch )全部耗尽的时候才去调用,而在此时刻可以根据一些信息调度进程,达到给每个用户平均分配 CPU 时间的效果。在 schedule() 函数选择了一个进程之后,它将判断是否需要重新计算进程的 counter 值,这个过程只有在运行队列中所有进程的都用完了时间片时才被调用。在这段代码中加入我们的算法是最合适不过的了。