http://dota2.uuu9.com/201904/591872.shtml
MMR算法
算法其实很简明。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |
注意事项
自走棋早期是公开MMR的,后来隐藏了,没有发现获取途径。
因为隐藏了,不好判断MMR系统有没有大改。不过隐藏前后没有体感到变化。
皇后分数上限早期是3400,没多久就突破了上限。
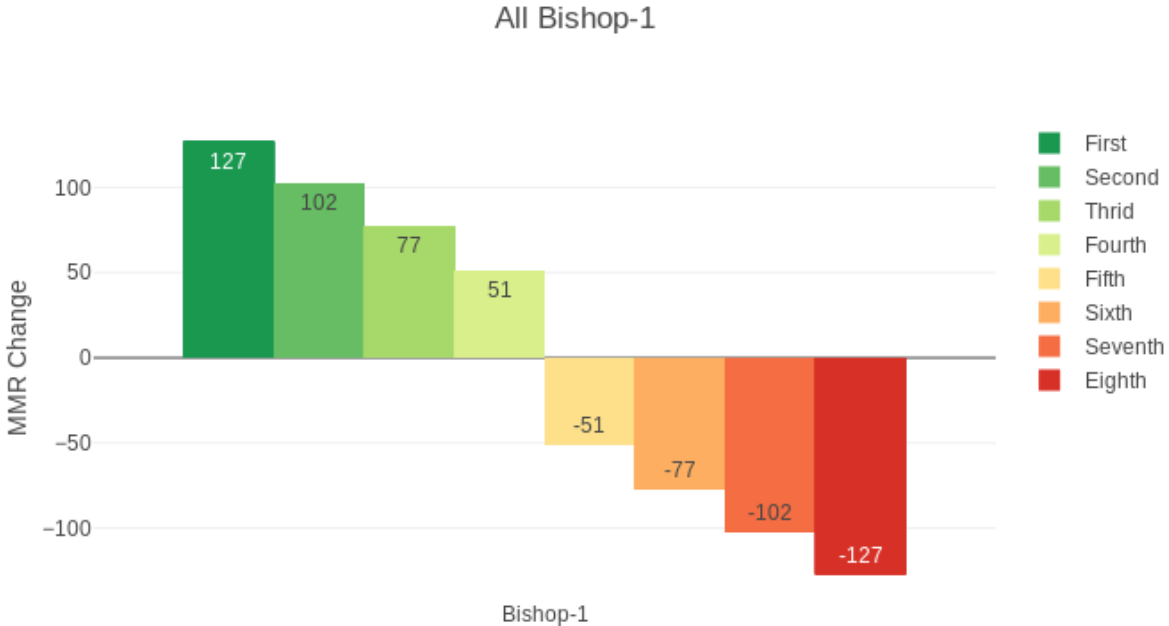
80分一段。房间里所有人同一段位时,第1名+127分,就是1.588个段位。第2名1.275个段位,第3名0.96个段位。第1名和第4名相差76分,第4名和第5名相差102分,这就是吃烂分的理论依据。
(存疑)如果第1名至少+15分,段位会通货膨胀。从整体数据观测,实际情况是主教人数向骑士滑移,主要原因是新账号(新人玩家或者小号)。具体参见:数说自走棋。
举例
下面的例子是模拟结果,感兴趣可以访问GitHub。
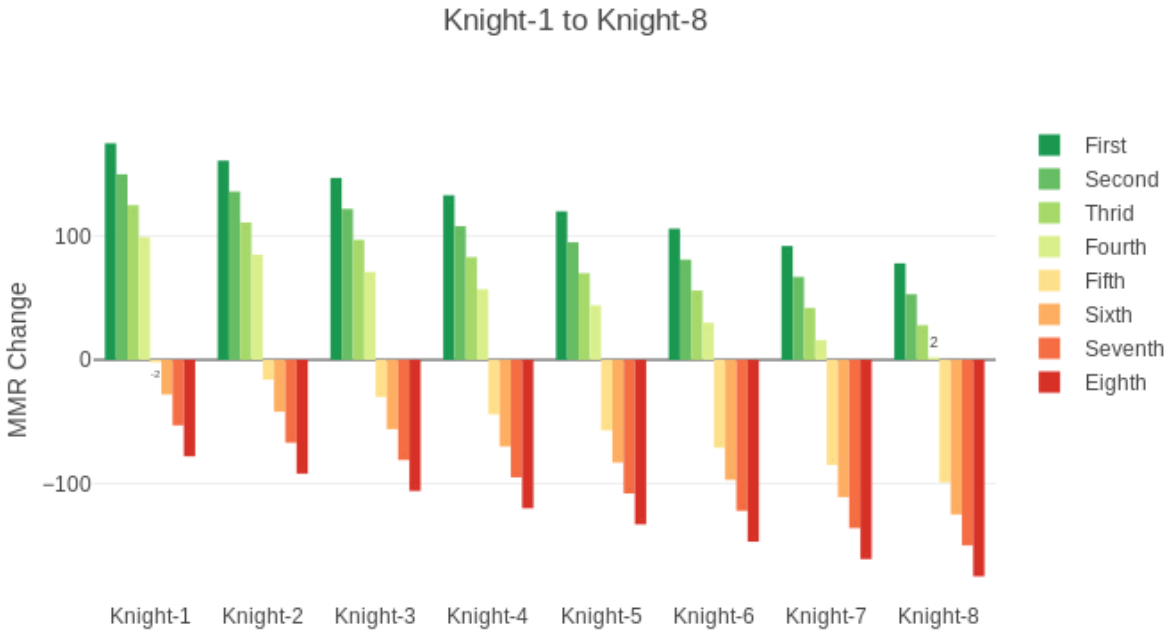
8个人分数一样时的情况如下。8个骑士2段和8个皇后的情况是一样的。
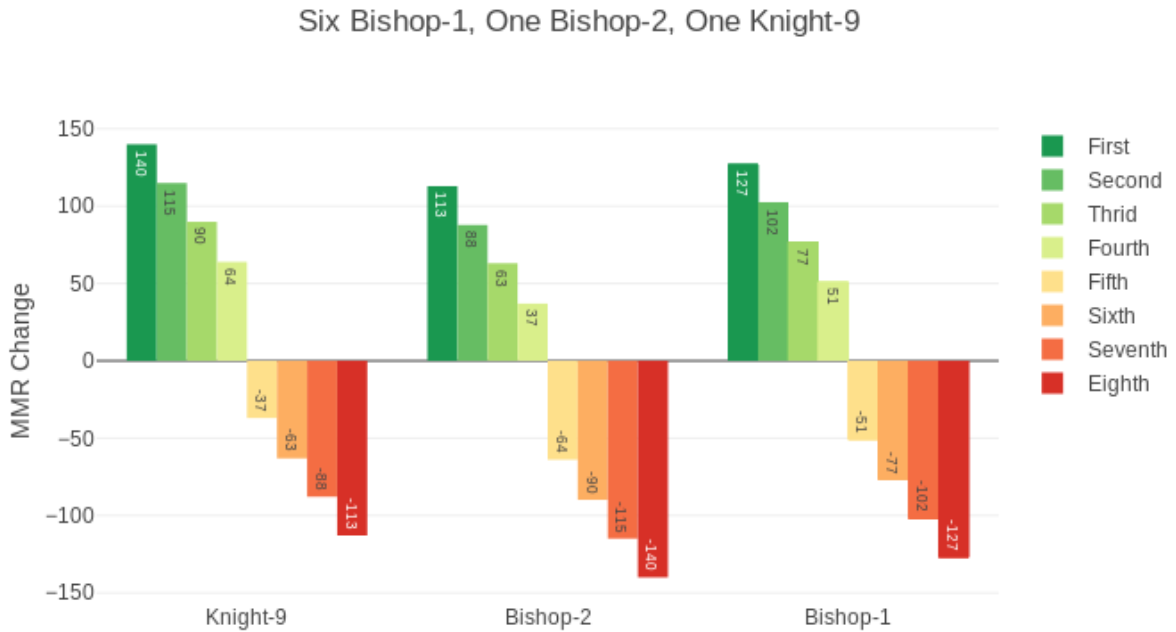
1个主教2,6个主教1和1个骑士9开主教局的情况:骑士9小赚,主教2小亏。其他分段情况类似,开局时分数最低的最赚,不过前4还是加分,后4还是掉分,只是数值上有差别。
房间里7个人分数一样,1个高其他人5段的情况。分数最高第4名扣分。
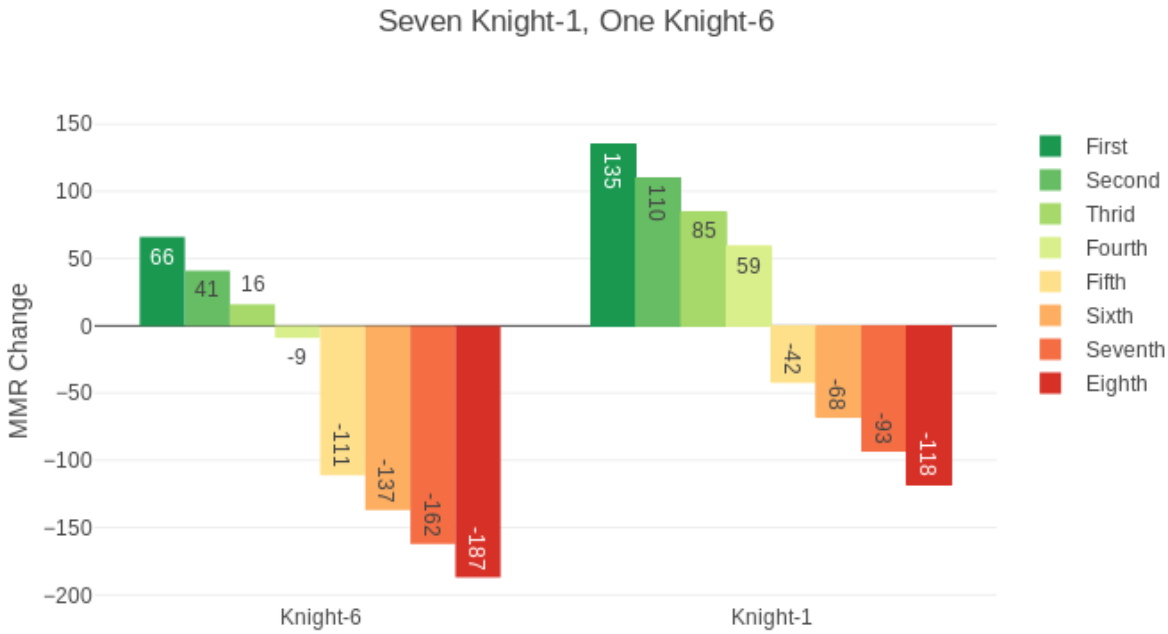
房间里7个人分数一样,1个高其他人7段的情况。分数最高第3名扣分。
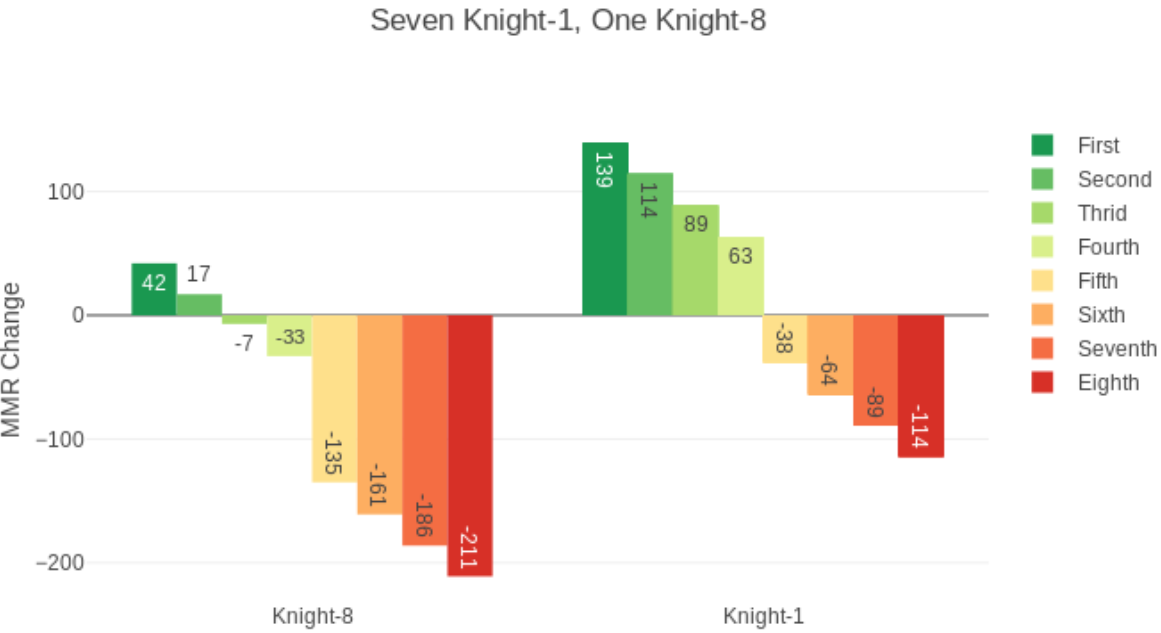
房间里7个人分数一样,1个高其他人9段的情况。分数最高第2名扣分。
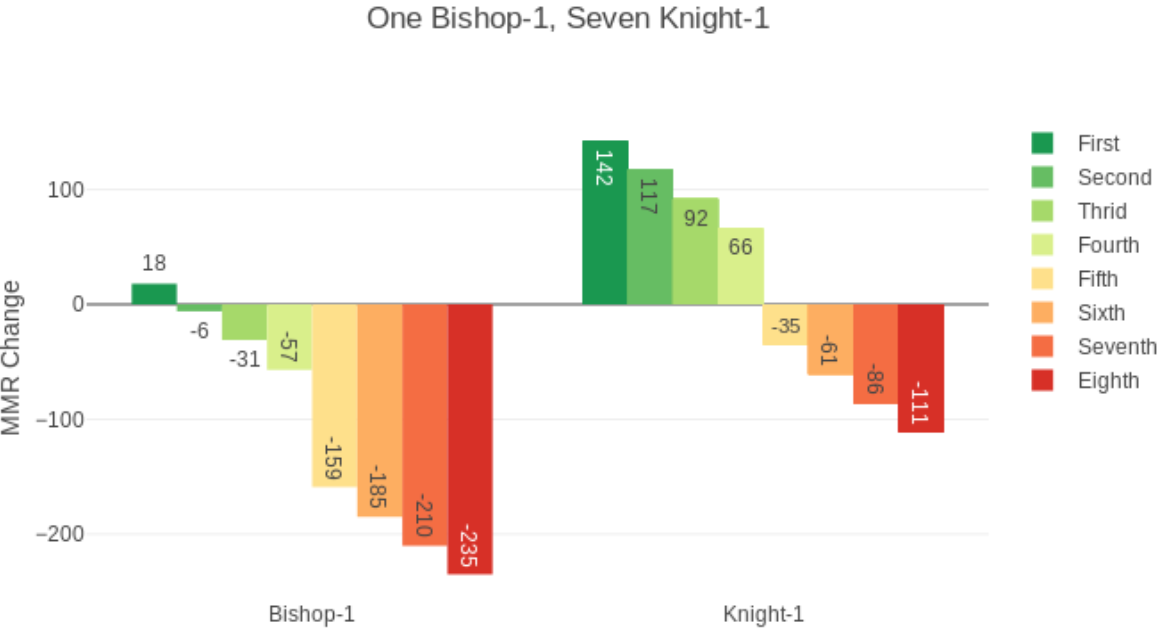
房间里7个人分数一样,1个高其他人10段的情况。分数最高的人第1名只+15分。
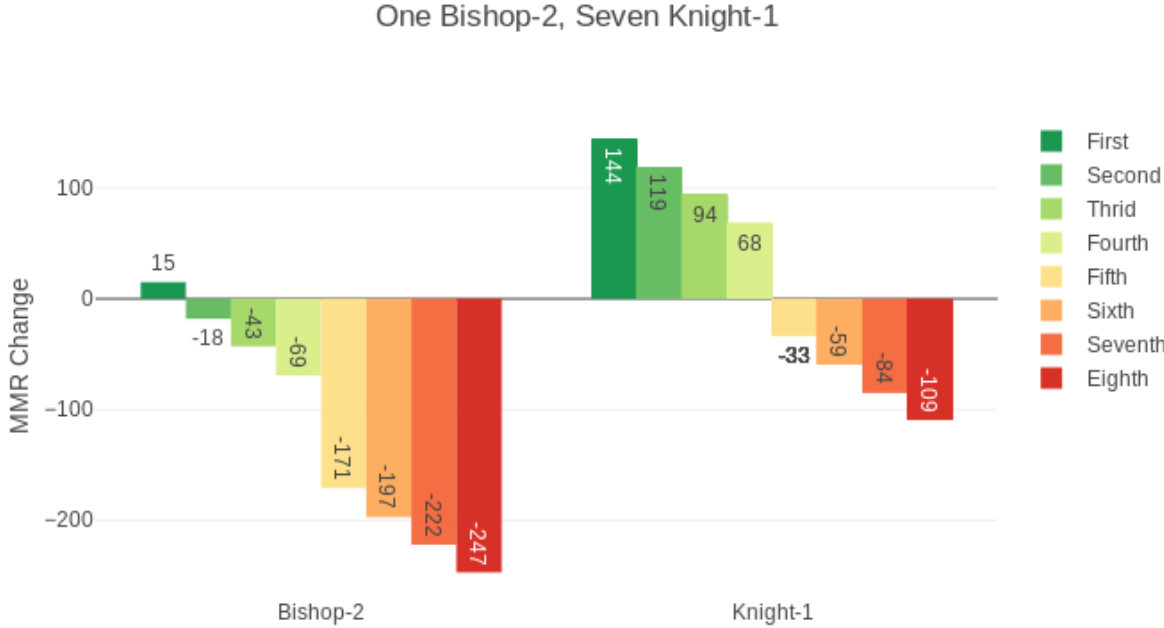
如果没有吃鸡最低+15分的规则,吃鸡不扣分的临界点你比平均分高736分,或者说你比其他7人平均段位高10.5段。高得再多吃鸡也要扣分。
如果没有吃鸡最低+15分的规则,1个3400分皇后号和7个0分士兵号匹配,皇后吃鸡了要扣386分,变成堡垒6段,要是不行第8飞了,对不起,堡垒3段。
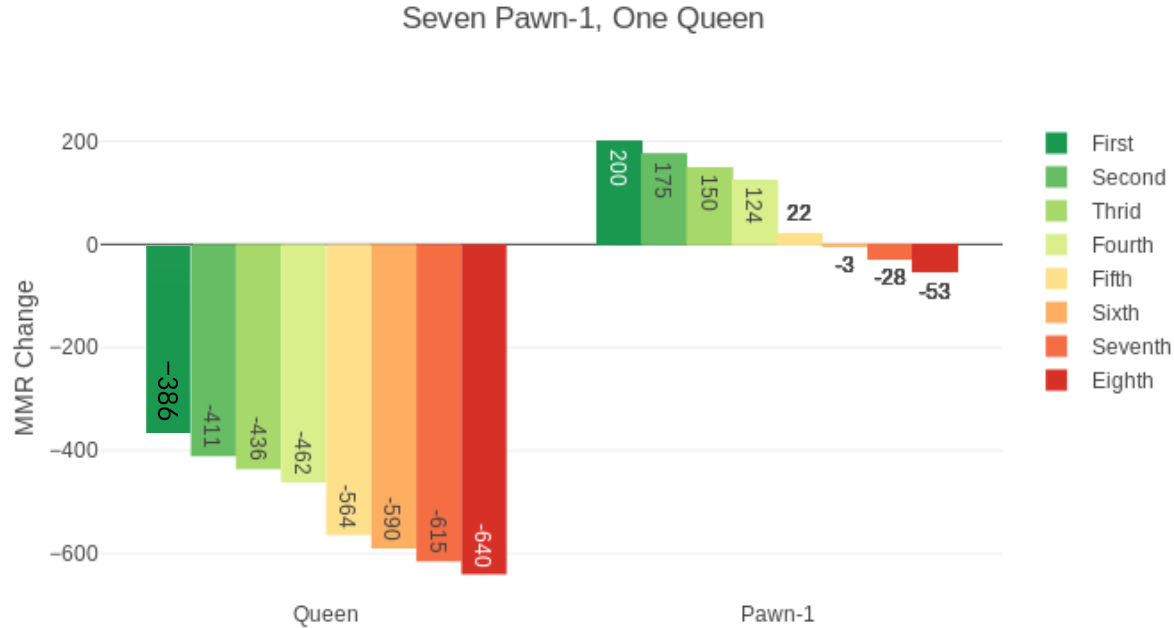
如果有吃鸡最低+15分的规则,-386变成+15,其他不变。
骑士1-8各1个的情况。骑士8段的玩家第4名只加2分,第1名加的分很少,比骑士1段的玩家吃鸡加的少很多。